Invoering
We introduceren DeepSeek-V3, een geavanceerd Mixture-of-Experts (MoE) taalmodel met een indrukwekkende 671 miljard totale parameters , die 37 miljard per token activeren. Ontworpen voor efficiënte inferentie en kosteneffectieve training , maakt DeepSeek-V3 gebruik van geavanceerde Multi-head Latent Attention (MLA) en DeepSeekMoE architecturen, die rigoureus werden gevalideerd in zijn voorganger, DeepSeek-V2.
DeepSeek-V3 betreedt nieuw terrein en implementeert een auxiliary-loss-free strategie voor load balancing en neemt een multi-token prediction objective aan, wat de algehele prestaties aanzienlijk verbetert. Het model ondergaat pre-training op 14,8 biljoen hoogwaardige, diverse tokens, gevolgd door Supervised Fine-Tuning en Reinforcement Learning- fasen om het potentieel volledig te ontsluiten.
Uitgebreide evaluaties bevestigen dat DeepSeek-V3 andere open-sourcemodellen overtreft en prestaties levert die vergelijkbaar zijn met die van toonaangevende closed-sourcesystemen. Ondanks deze hoogwaardige capaciteit, bereikt DeepSeek-V3 een uitzonderlijke trainingsefficiëntie, waarbij slechts 2,788 miljoen H800 GPU-uren nodig zijn voor volledige training. Bovendien blijft het trainingsproces opmerkelijk stabiel : er zijn geen onherstelbare verliespieken of rollbacks opgetreden gedurende de gehele trainingsfase.
Model Samenvatting
Architectuur: Innovatieve Load Balancing Strategie en Multi-Token Training Doelstelling
- Voortbouwend op de efficiënte architectuur van DeepSeek-V2 , is DeepSeek-V3 een pionier in een auxiliaire-verliesvrije load balancing-strategie , die effectief de typische prestatieverslechtering minimaliseert die geassocieerd wordt met traditionele load balancing-benaderingen. Deze innovatie verbetert de modelefficiëntie zonder de nauwkeurigheid in gevaar te brengen.
- Verder introduceren we een Multi-Token Prediction (MTP)-doelstelling , die niet alleen de modelprestaties verbetert, maar ook speculatieve decodering mogelijk maakt , waardoor de snelheid van de gevolgtrekking aanzienlijk wordt versneld.
Pre-training: ongeëvenaarde trainingsefficiëntie bereiken
- DeepSeek-V3 maakt gebruik van een geavanceerd FP8 mixed-precision trainingsframework , wat de eerste succesvolle validatie van FP8-training op een model op deze schaal markeert . Door algoritmen, frameworks en hardware samen te ontwerpen, elimineren we communicatieknelpunten tussen knooppunten in MoE-training, waardoor een bijna volledige overlapping van berekeningen en communicatie wordt bereikt.
- Deze optimalisatie verhoogt de trainingsefficiëntie en verlaagt de kosten, waardoor we de modelgrootte verder kunnen opschalen zonder extra overhead.
- Tegen een economische kostprijs van slechts 2,664 miljoen H800 GPU-uren , trainen we DeepSeek-V3 vooraf op 14,8 biljoen tokens , waarmee we het tot het sterkste open-source basismodel maken dat beschikbaar is. De daaropvolgende trainingsfasen, inclusief supervised fine-tuning en reinforcement learning, vereisen slechts 0,1 miljoen extra GPU-uren.
Na de training: kennisdestillatie van DeepSeek-R1
- Om de redeneercapaciteiten te verbeteren, integreren we een innovatieve kennisdistillatiepijplijn die put uit DeepSeek-R1 lange Chain-of-Thought (CoT)-model. Deze methodologie integreert naadloos verificatie- en reflectiepatronen van R1 in DeepSeek-V3, wat resulteert in opmerkelijke verbeteringen in de redeneerprestaties.
- Bovendien houden we nauwlettend toezicht op de uitvoerstijl en -lengte van DeepSeek-V3 , waardoor consistentie en betrouwbaarheid in verschillende use cases worden gewaarborgd.
Download het model
| Model | #Totale Parameters | #Geactiveerde Parameters | Contextlengte | Download |
|---|---|---|---|---|
| DeepSeek-V3-Basis | 671B | 37B | 128K | 🤗 Hugging Face |
| DeepSeek-V3 | 671B | 37B | 128K | 🤗 Hugging Face |
De totale grootte van DeepSeek-V3 op Hugging Face is 685 miljard parameters , bestaande uit 671B voor de Main Model-gewichten en 14B voor de Multi-Token Prediction (MTP) Module . Deze modulaire structuur zorgt voor zowel optimale prestaties als flexibiliteit , waardoor gebruikers het model kunnen aanpassen aan specifieke taken en resourcebeperkingen.
Om een breed scala aan implementatiescenario’s te ondersteunen, hebben we nauw samengewerkt met open-sourcecommunity’s en hardwareleveranciers , en bieden we meerdere manieren om DeepSeek-V3 lokaal uit te voeren . Raadpleeg Sectie 6: How_to_Run_Locally in de documentatie voor stapsgewijze instructies.
Voor ontwikkelaars die geïnteresseerd zijn in een dieper begrip van de modelarchitectuur en parameters, biedt README_WEIGHTS.md gedetailleerde inzichten in zowel de Main Model-gewichten als de MTP-module . Houd er rekening mee dat MTP-ondersteuning nog steeds actief wordt ontwikkeld door de community. We moedigen bijdragen, feedback en samenwerking aan om de mogelijkheden ervan te verfijnen en uit te breiden.
Evaluatieresultaten
Basismodel
Standaard benchmarks
| Benchmark (Metric) | # Shots | DeepSeek-V2 | Qwen2.5 72B | LLaMA3.1 405B | DeepSeek-V3 |
|---|---|---|---|---|---|
| Architecture | – | MoE | Dense | Dense | MoE |
| # Activated Params | – | 21B | 72B | 405B | 37B |
| # Total Params | – | 236B | 72B | 405B | 671B |
| English Pile-test (BPB) | – | 0.606 | 0.638 | 0.542 | 0.548 |
| BBH (EM) | 3-shot | 78.8 | 79.8 | 82.9 | 87.5 |
| MMLU (Acc.) | 5-shot | 78.4 | 85.0 | 84.4 | 87.1 |
| MMLU-Redux (Acc.) | 5-shot | 75.6 | 83.2 | 81.3 | 86.2 |
| MMLU-Pro (Acc.) | 5-shot | 51.4 | 58.3 | 52.8 | 64.4 |
| DROP (F1) | 3-shot | 80.4 | 80.6 | 86.0 | 89.0 |
| ARC-Easy (Acc.) | 25-shot | 97.6 | 98.4 | 98.4 | 98.9 |
| ARC-Challenge (Acc.) | 25-shot | 92.2 | 94.5 | 95.3 | 95.3 |
| HellaSwag (Acc.) | 10-shot | 87.1 | 84.8 | 89.2 | 88.9 |
| PIQA (Acc.) | 0-shot | 83.9 | 82.6 | 85.9 | 84.7 |
| WinoGrande (Acc.) | 5-shot | 86.3 | 82.3 | 85.2 | 84.9 |
| RACE-Middle (Acc.) | 5-shot | 73.1 | 68.1 | 74.2 | 67.1 |
| RACE-High (Acc.) | 5-shot | 52.6 | 50.3 | 56.8 | 51.3 |
| TriviaQA (EM) | 5-shot | 80.0 | 71.9 | 82.7 | 82.9 |
| NaturalQuestions (EM) | 5-shot | 38.6 | 33.2 | 41.5 | 40.0 |
| AGIEval (Acc.) | 0-shot | 57.5 | 75.8 | 60.6 | 79.6 |
| Code HumanEval (Pass@1) | 0-shot | 43.3 | 53.0 | 54.9 | 65.2 |
| MBPP (Pass@1) | 3-shot | 65.0 | 72.6 | 68.4 | 75.4 |
| LiveCodeBench-Base (Pass@1) | 3-shot | 11.6 | 12.9 | 15.5 | 19.4 |
| CRUXEval-I (Acc.) | 2-shot | 52.5 | 59.1 | 58.5 | 67.3 |
| CRUXEval-O (Acc.) | 2-shot | 49.8 | 59.9 | 59.9 | 69.8 |
| Math GSM8K (EM) | 8-shot | 81.6 | 88.3 | 83.5 | 89.3 |
| MATH (EM) | 4-shot | 43.4 | 54.4 | 49.0 | 61.6 |
| MGSM (EM) | 8-shot | 63.6 | 76.2 | 69.9 | 79.8 |
| CMath (EM) | 3-shot | 78.7 | 84.5 | 77.3 | 90.7 |
| Chinese CLUEWSC (EM) | 5-shot | 82.0 | 82.5 | 83.0 | 82.7 |
| C-Eval (Acc.) | 5-shot | 81.4 | 89.2 | 72.5 | 90.1 |
| CMMLU (Acc.) | 5-shot | 84.0 | 89.5 | 73.7 | 88.8 |
| CMRC (EM) | 1-shot | 77.4 | 75.8 | 76.0 | 76.3 |
| C3 (Acc.) | 0-shot | 77.4 | 76.7 | 79.7 | 78.6 |
| CCPM (Acc.) | 0-shot | 93.0 | 88.5 | 78.6 | 92.0 |
| Multilingual MMMLU-non-English (Acc.) | 5-shot | 64.0 | 74.8 | 73.8 | 79.4 |
De beste resultaten zijn vetgedrukt. Scores binnen een marge van 0,3 worden als gelijkwaardig in prestaties beschouwd. DeepSeek-V3 behaalt consequent topresultaten in de meeste benchmarks, en blinkt met name uit in wiskunde- en coderingstaken. Raadpleeg ons gedetailleerde evaluatieartikel voor een uitgebreide analyse.
Contextvenster
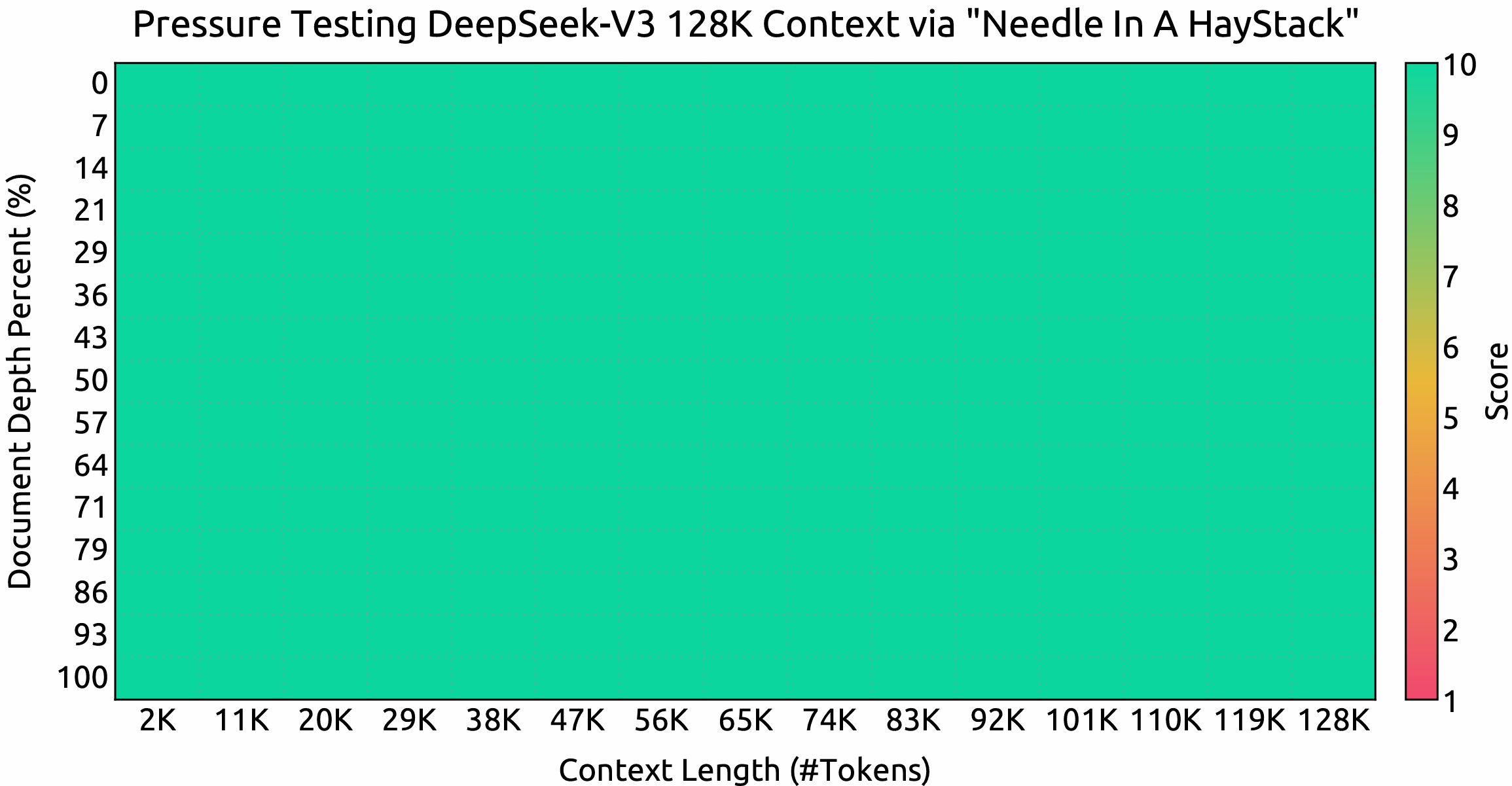
DeepSeek-V3 presteert uitzonderlijk goed bij Needle In A Haystack (NIAH)-evaluaties. Het navigeert en verwerkt efficiënt uitgebreide contexten tot 128.000 tokens met een hoge nauwkeurigheid en consistentie.
Chatmodel
Standaard Benchmarks (Modellen groter dan 67B)
| Benchmark (Metric) | DeepSeek V2-0506 | DeepSeek V2.5-0905 | Qwen2.5 72B-Inst. | Llama3.1 405B-Inst. | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 |
|---|---|---|---|---|---|---|---|
| Architecture | MoE | MoE | Dense | Dense | – | – | MoE |
| # Activated Params | 21B | 21B | 72B | 405B | – | – | 37B |
| # Total Params | 236B | 236B | 72B | 405B | – | – | 671B |
| English MMLU (EM) | 78.2 | 80.6 | 85.3 | 88.6 | 88.3 | 87.2 | 88.5 |
| MMLU-Redux (EM) | 77.9 | 80.3 | 85.6 | 86.2 | 88.9 | 88.0 | 89.1 |
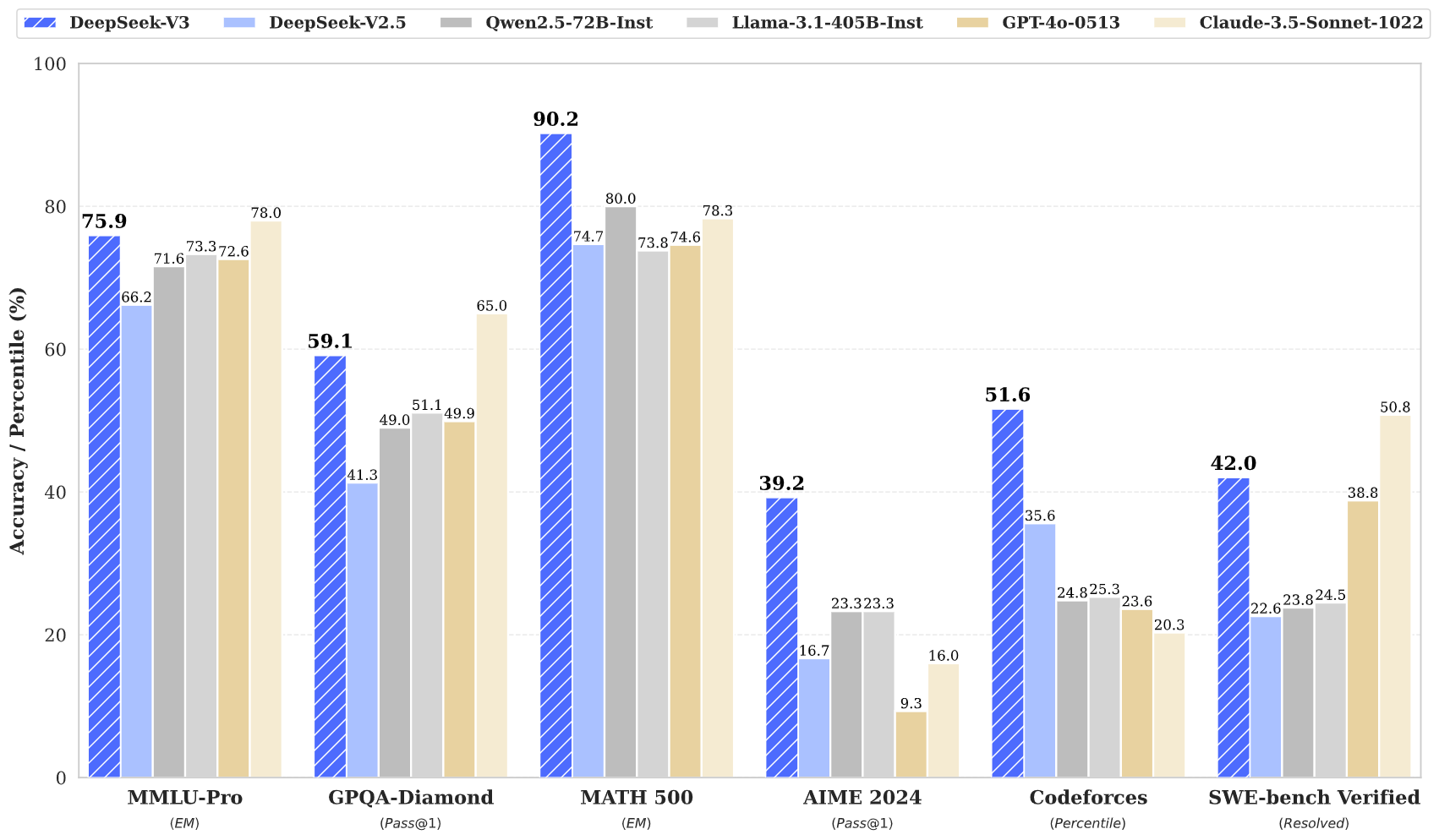
| MMLU-Pro (EM) | 58.5 | 66.2 | 71.6 | 73.3 | 78.0 | 72.6 | 75.9 |
| DROP (3-shot F1) | 83.0 | 87.8 | 76.7 | 88.7 | 88.3 | 83.7 | 91.6 |
| IF-Eval (Prompt Strict) | 57.7 | 80.6 | 84.1 | 86.0 | 86.5 | 84.3 | 86.1 |
| GPQA-Diamond (Pass@1) | 35.3 | 41.3 | 49.0 | 51.1 | 65.0 | 49.9 | 59.1 |
| SimpleQA (Correct) | 9.0 | 10.2 | 9.1 | 17.1 | 28.4 | 38.2 | 24.9 |
| FRAMES (Acc.) | 66.9 | 65.4 | 69.8 | 70.0 | 72.5 | 80.5 | 73.3 |
| LongBench v2 (Acc.) | 31.6 | 35.4 | 39.4 | 36.1 | 41.0 | 48.1 | 48.7 |
| Code HumanEval-Mul (Pass@1) | 69.3 | 77.4 | 77.3 | 77.2 | 81.7 | 80.5 | 82.6 |
| LiveCodeBench (Pass@1-COT) | 18.8 | 29.2 | 31.1 | 28.4 | 36.3 | 33.4 | 40.5 |
| LiveCodeBench (Pass@1) | 20.3 | 28.4 | 28.7 | 30.1 | 32.8 | 34.2 | 37.6 |
| Codeforces (Percentile) | 17.5 | 35.6 | 24.8 | 25.3 | 20.3 | 23.6 | 51.6 |
| SWE Verified (Resolved) | – | 22.6 | 23.8 | 24.5 | 50.8 | 38.8 | 42.0 |
| Aider-Edit (Acc.) | 60.3 | 71.6 | 65.4 | 63.9 | 84.2 | 72.9 | 79.7 |
| Aider-Polyglot (Acc.) | – | 18.2 | 7.6 | 5.8 | 45.3 | 16.0 | 49.6 |
| Math AIME 2024 (Pass@1) | 4.6 | 16.7 | 23.3 | 23.3 | 16.0 | 9.3 | 39.2 |
| MATH-500 (EM) | 56.3 | 74.7 | 80.0 | 73.8 | 78.3 | 74.6 | 90.2 |
| CNMO 2024 (Pass@1) | 2.8 | 10.8 | 15.9 | 6.8 | 13.1 | 10.8 | 43.2 |
| Chinese CLUEWSC (EM) | 89.9 | 90.4 | 91.4 | 84.7 | 85.4 | 87.9 | 90.9 |
| C-Eval (EM) | 78.6 | 79.5 | 86.1 | 61.5 | 76.7 | 76.0 | 86.5 |
| C-SimpleQA (Correct) | 48.5 | 54.1 | 48.4 | 50.4 | 51.3 | 59.3 | 64.8 |
Alle modellen worden geëvalueerd met een outputlengte die is gemaximaliseerd op 8K tokens. Voor benchmarks met minder dan 1.000 samples worden meerdere tests uitgevoerd met verschillende temperatuurinstellingen om robuuste en betrouwbare eindresultaten te garanderen. DeepSeek-V3 komt naar voren als het best presterende open-sourcemodel, terwijl het ook concurrerende prestaties laat zien ten opzichte van toonaangevende closed-sourcemodellen.
Open Generatie Evaluatie
| Model | Arena-Hard | AlpacaEval 2.0 |
|---|---|---|
| DeepSeek-V2.5-0905 | 76.2 | 50.5 |
| Qwen2.5-72B-Instrueren | 81.2 | 49.1 |
| LLaMA-3.1 405B | 69.3 | 40.5 |
| GPT-4o-0513 | 80.4 | 51.1 |
| Claude-Sonnet-3.5-1022 | 85.2 | 52.0 |
| DeepSeek-V3 | 85.5 | 70.0 |
Evaluaties van open Engelse conversaties worden uitgevoerd met behulp van AlpacaEval 2.0, waarbij het op lengte gebaseerde winstpercentage als primaire prestatiemaatstaf dient.
Chatwebsite en API-platform
Communiceer rechtstreeks met DeepSeek-V3 op de officiële chatwebsite van DeepSeek op chat.deepseek.com .
Voor naadloze integratie in uw applicaties bieden wij een OpenAI-compatibele API via het DeepSeek-platform op platform.deepseek.com .
Contact
Voor vragen of ondersteuningsverzoeken kunt u gerust een probleem melden of contact met ons opnemen via [email protected]. Ons team staat voor u klaar bij DeepSeekNederlands.nl. – Bekijk hier de tutorial over het uitvoeren van het DeepSeek-V3-model !