
Introductie van DeepSeek Coder
DeepSeek Coder bestaat uit een reeks high-performance codetaalmodellen, elk vanaf nul getraind op 2 biljoen tokens . De trainingsdataset bestaat uit 87% code en 13% natuurlijke taal, en omvat zowel Engels als Chinees. De modelfamilie omvat versies variërend van 1B tot 33B parameters.
Elk model is vooraf getraind op een codecorpus op projectniveau met behulp van een contextvenster van 16K en een extra invultaak, waardoor ondersteuning voor codeaanvulling en code-invulling op projectniveau mogelijk is.
Wat betreft coderingsmogelijkheden levert DeepSeek Coder de allernieuwste prestaties in open-sourcemodellen in meerdere programmeertalen en benchmarks. Daarmee is het een toonaangevende oplossing voor geavanceerde codegeneratie en het begrijpen van taken.
- Enorme trainingsdata: vanaf nul getraind op 2 biljoen tokens , bestaande uit 87% code en 13% taalkundige data in het Engels en Chinees voor uitgebreide dekking en nauwkeurigheid.
- Zeer flexibel en schaalbaar: verkrijgbaar in meerdere modelgroottes: 1B, 5,7B, 6,7B en 33B , zodat gebruikers de meest geschikte configuratie voor hun specifieke behoeften kunnen selecteren.
- Superieure modelprestaties: behaalt state-of-the-art resultaten tussen open-source codemodellen op belangrijke benchmarks, waaronder HumanEval, MultiPL-E , MBPP , DS-1000 en APPS.
- Geavanceerde mogelijkheden voor codeaanvulling: beschikt over een contextvenster van 16K en een invultaak , waarmee codeaanvulling en code-invulling op projectniveau mogelijk zijn voor verbeterde functionaliteit.
Evaluatieresultaten
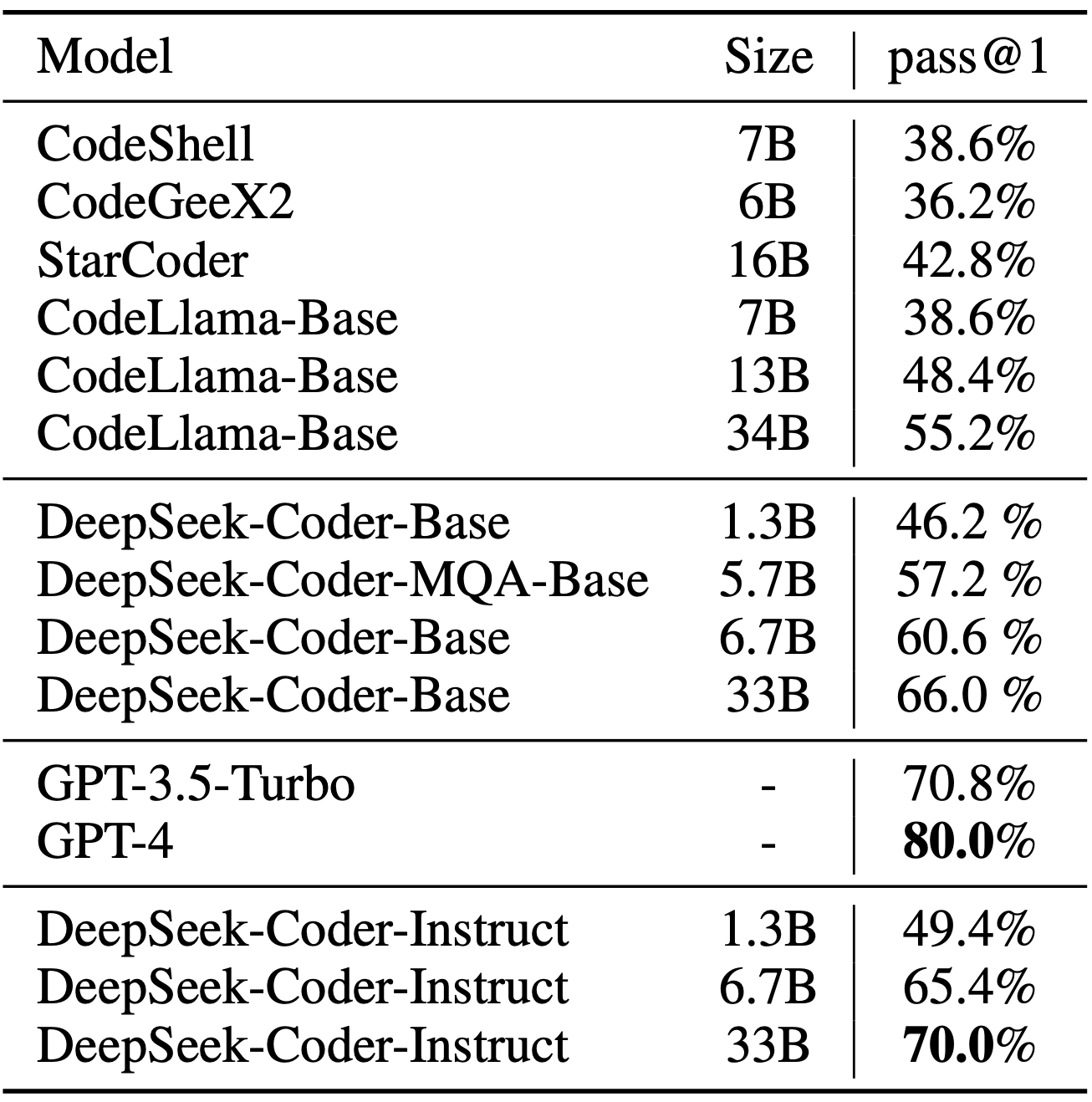
We hebben DeepSeek Coder geëvalueerd aan de hand van verschillende benchmarks op het gebied van codering, waarbij we ons vooral richtten op pass@1 -resultaten voor HumanEval (Python en meertalig) , MBPP en DS-1000.
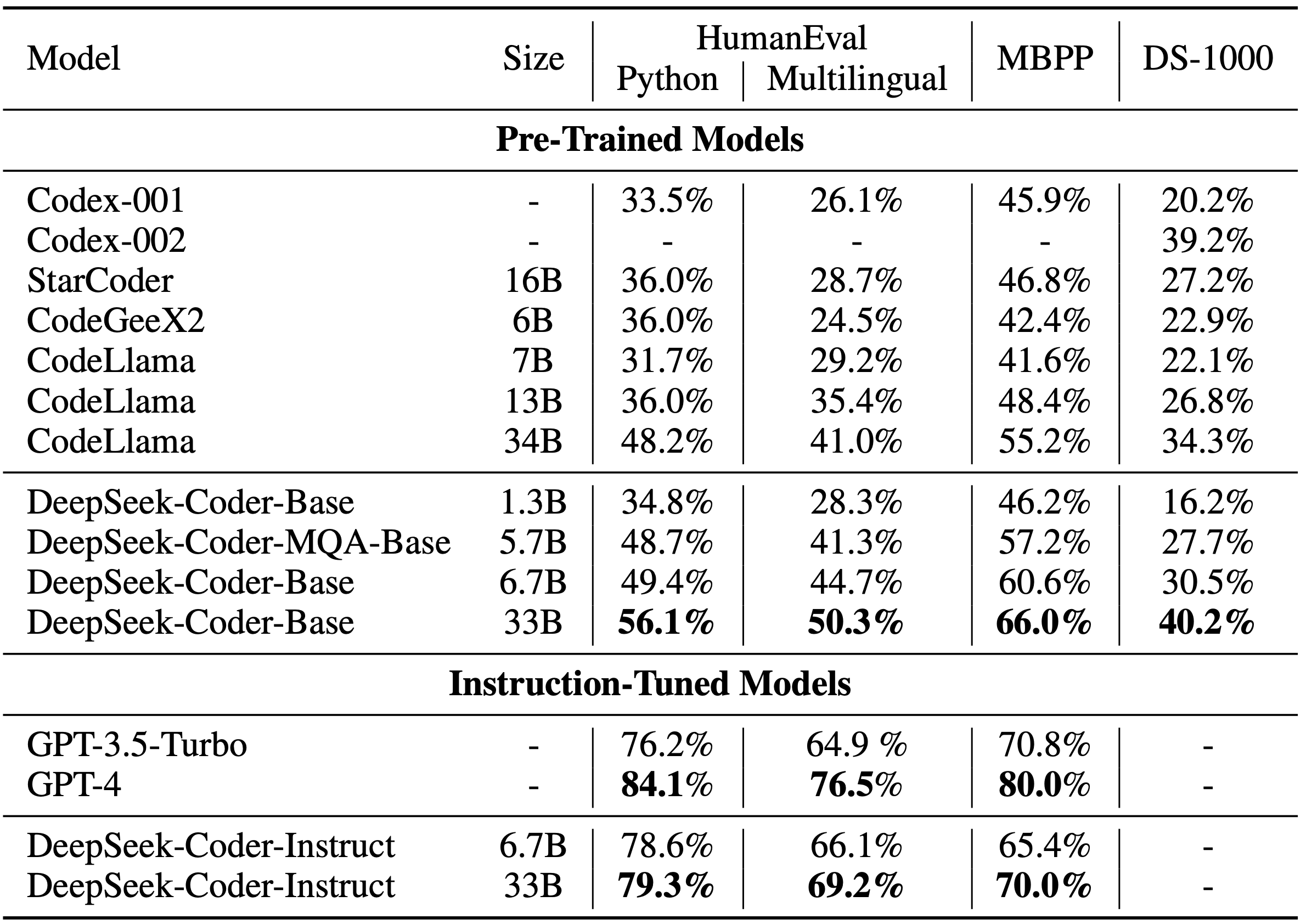
De resultaten tonen aan dat DeepSeek-Coder-Base-33B aanzienlijk beter presteert dan bestaande open-source code LLM’s. Vergeleken met CodeLlama-34B behaalt het verbeteringen van 7,9% , 9,3% , 10,8% en 5,9% op respectievelijk HumanEval Python , HumanEval Multilingual , MBPP en DS-1000.
Opvallend is dat DeepSeek-Coder-Base-7B de prestaties van CodeLlama-34B evenaart , wat zijn opmerkelijke efficiëntie laat zien. Na instructie-afstemming overtreft DeepSeek-Coder-Instruct-33B GPT-3.5-turbo op HumanEval en levert vergelijkbare resultaten met GPT-3.5-turbo op MBPP , wat zijn geavanceerde coderingsmogelijkheden en praktische bruikbaarheid benadrukt.
Procedure voor het maken van gegevens en het trainen van modellen
Gegevenscreatie
Stap 1: Verzamel codegegevens van GitHub , waarbij u dezelfde filterregels toepast als StarCoder Data om een hoogwaardige gegevensselectie te garanderen. Deze stap verwijdert irrelevante of lage kwaliteit gegevens vroeg in het proces.
Stap 2: Parseer bestandsafhankelijkheden binnen dezelfde repository om bestandsposities opnieuw te ordenen op basis van hun afhankelijkheidsstructuur. Dit zorgt ervoor dat de logische volgorde van bestanden behouden blijft voor beter leren en begrijpen.
Stap 3: Concateneer afhankelijke bestanden om een enkel samenhangend voorbeeld te vormen, waardoor het model context op projectniveau kan verwerken . Gebruik MinHash op repo-niveau voor deduplicatie , zodat u unieke voorbeelden verzekert en redundante gegevens voorkomt.
Stap 4: Filter code van lage kwaliteit , inclusief bestanden met syntaxisfouten , slechte opmaak of onleesbare structuur. Deze laatste stap verbetert de algehele kwaliteit van de dataset, zodat alleen schone en betrouwbare code wordt gebruikt voor training.

Modeltraining
Stap 1: Het model is vooraf getraind op een dataset die bestaat uit 87% code , 10% codegerelateerde taal (bijv. GitHub Markdown en StackExchange ) en 3% niet-codegerelateerde Chinese taal . Deze stap omvat training op 1,8 biljoen tokens met behulp van een 4K-contextvenster , wat de basis vormt voor taal- en codebegrip.
Stap 2: Om de mogelijkheden voor lange contexten te verbeteren, ondergaat het model verdere pre-training met een uitgebreid 16K-contextvenster op nog eens 200 miljard tokens . Dit resulteert in de creatie van DeepSeek-Coder-Base- modellen, die zijn geoptimaliseerd voor het verwerken van grotere contextvensters en complexe codeafhankelijkheden.
Stap 3: In de laatste stap wordt het model fine-tuned met behulp van 2 miljard tokens aan instructiedata , wat DeepSeek-Coder-Instruct- modellen oplevert. Dit fine-tuningproces richt zich op het verbeteren van het vermogen van het model om instructies te volgen en gespecialiseerde coderingstaken uit te voeren, wat de praktische bruikbaarheid aanzienlijk verbetert.

Gedetailleerde evaluatieresultaten
De reproduceerbare code voor de evaluatieresultaten is beschikbaar in de Evaluatiedirectory , zodat gebruikers de benchmarks kunnen verifiëren en repliceren.
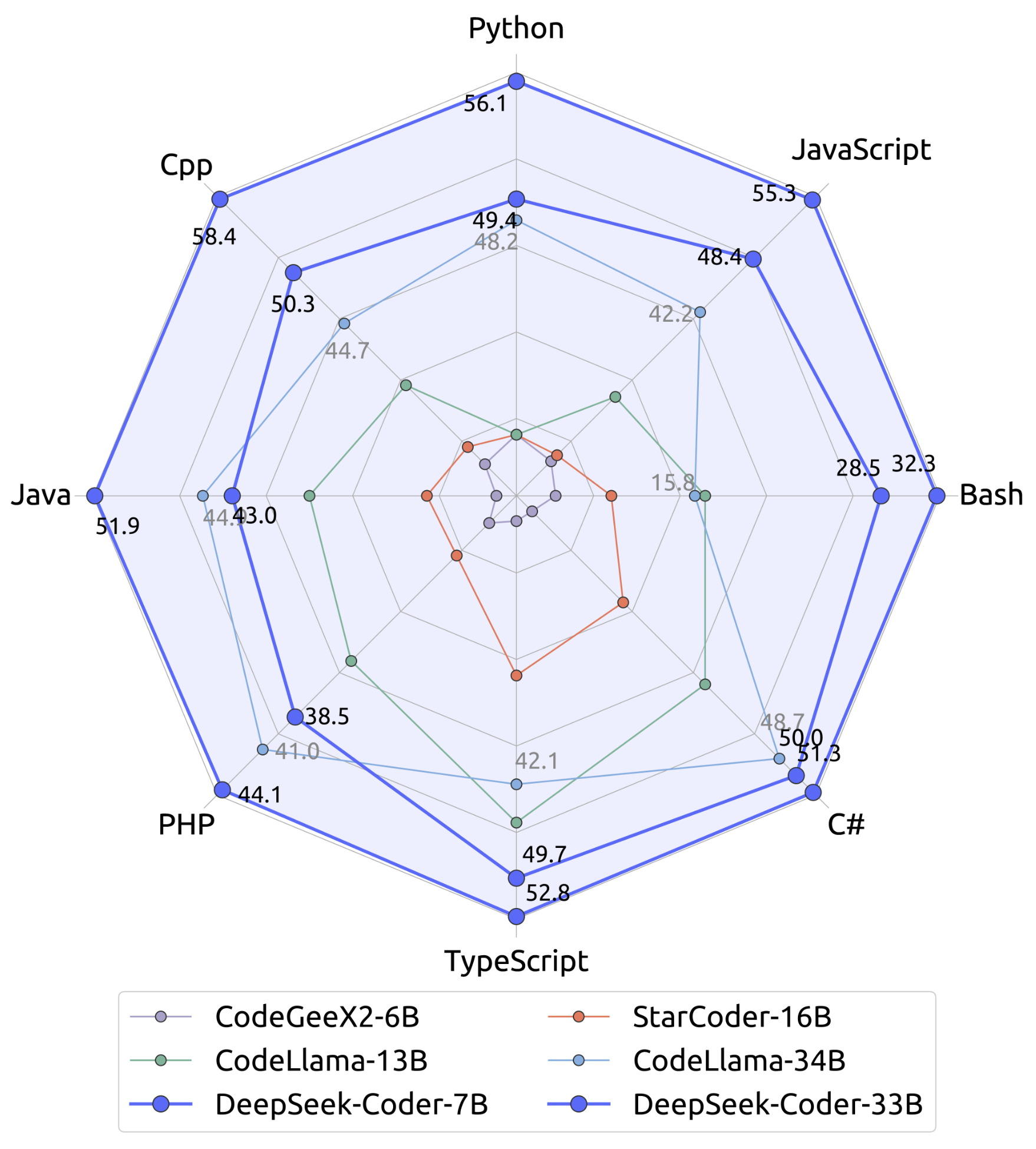
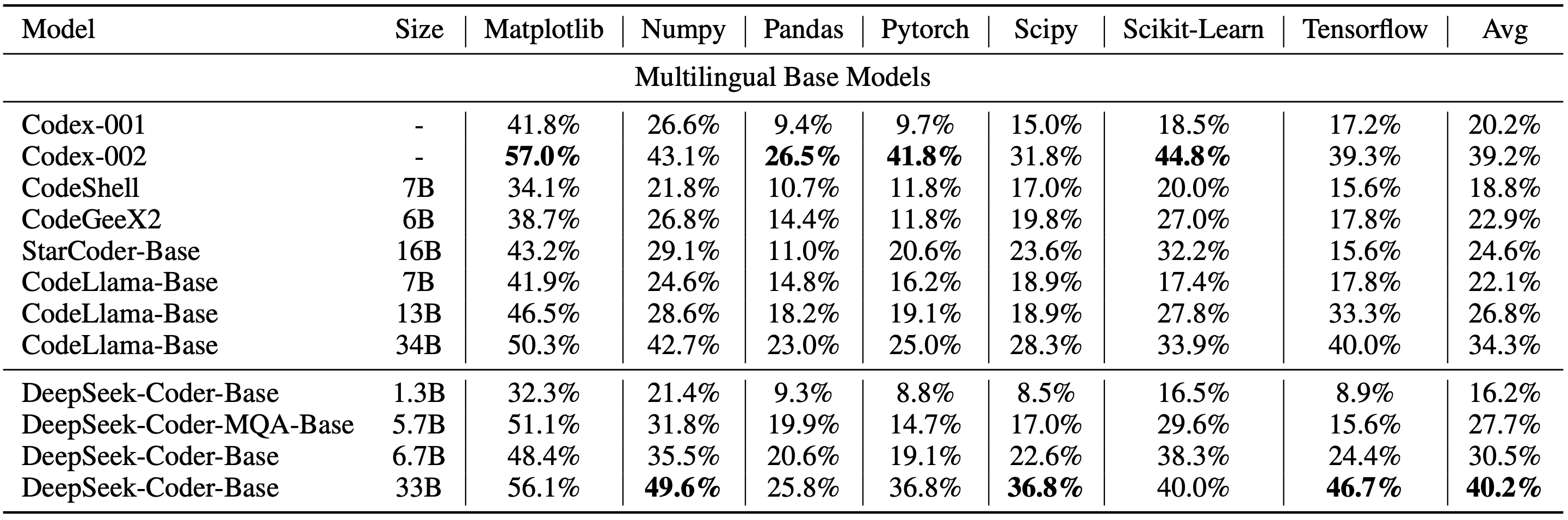
Meertalige HumanEval Benchmark
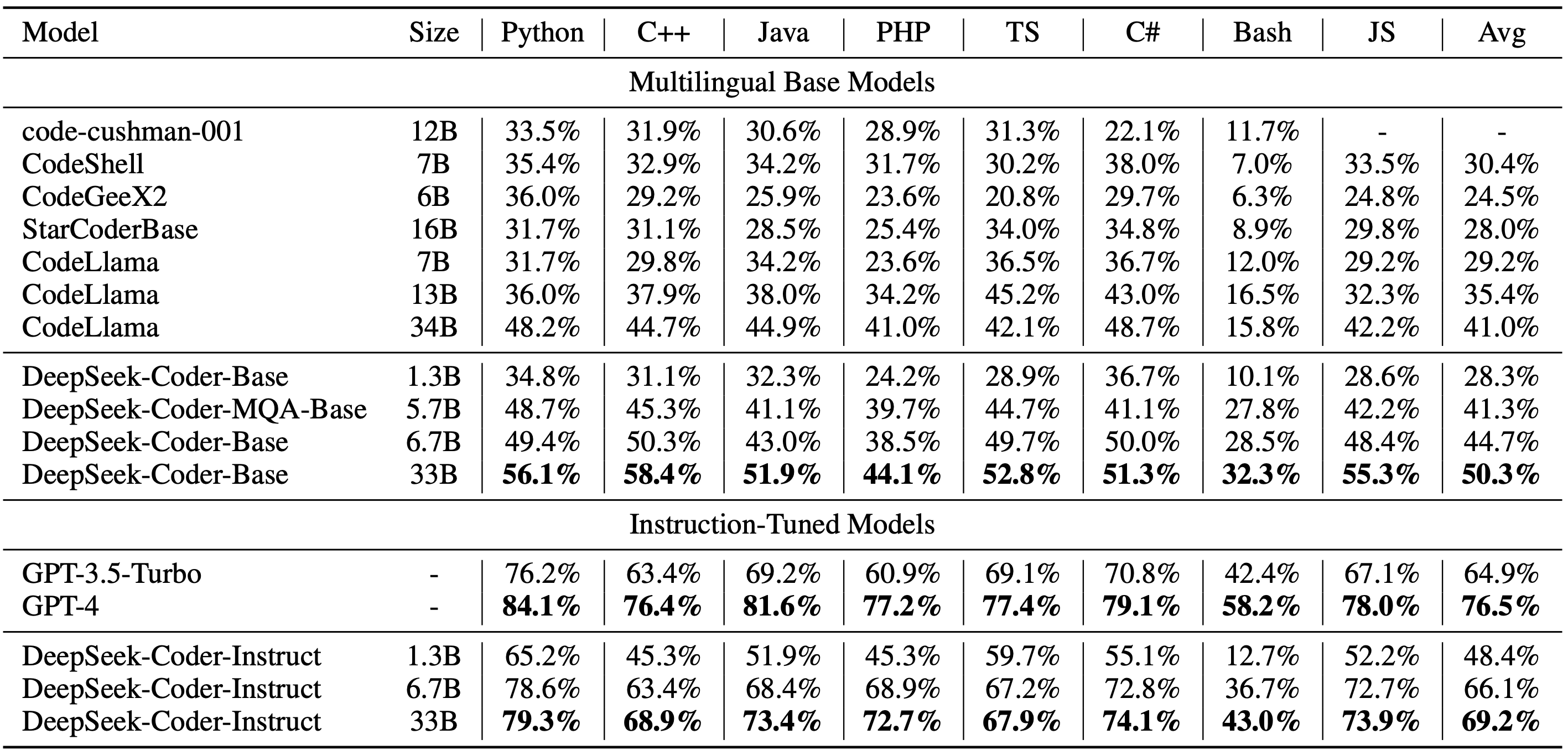
MBPP-benchmark
DS-1000-benchmark
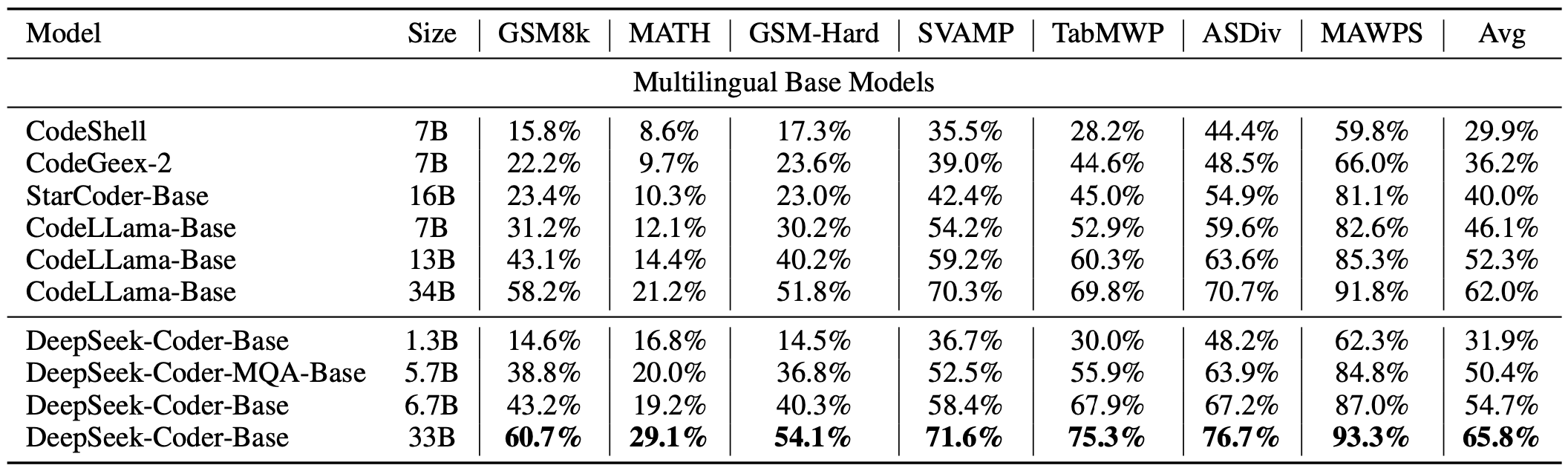
Programma-hulp wiskunde redeneerbenchmark
Hulpbronnen
awesome-deepseek-coder is een zorgvuldig samengestelde verzameling open-sourceprojecten en -bronnen met betrekking tot DeepSeek Coder . Hierin worden tools, implementaties en bijdragen van de community getoond om de mogelijkheden van codering en AI te verbeteren.
Contact
Als u vragen hebt of ondersteuning nodig hebt, kunt u een probleem melden in de DeepSeek-repository of rechtstreeks contact met ons opnemen via [email protected] op DeepSeekNederlands.nl – Bekijk hier de tutorial over het uitvoeren van het DeepSeek-Coder-model!