Inleiding
DeepSeek-Math is gebaseerd op DeepSeek-Coder-v1 5 7B en ondergaat voortdurende voortraining op 500 miljard wiskunde-gerelateerde tokens afkomstig van Common Crawl , samen met natuurlijke taal en codegegevens.
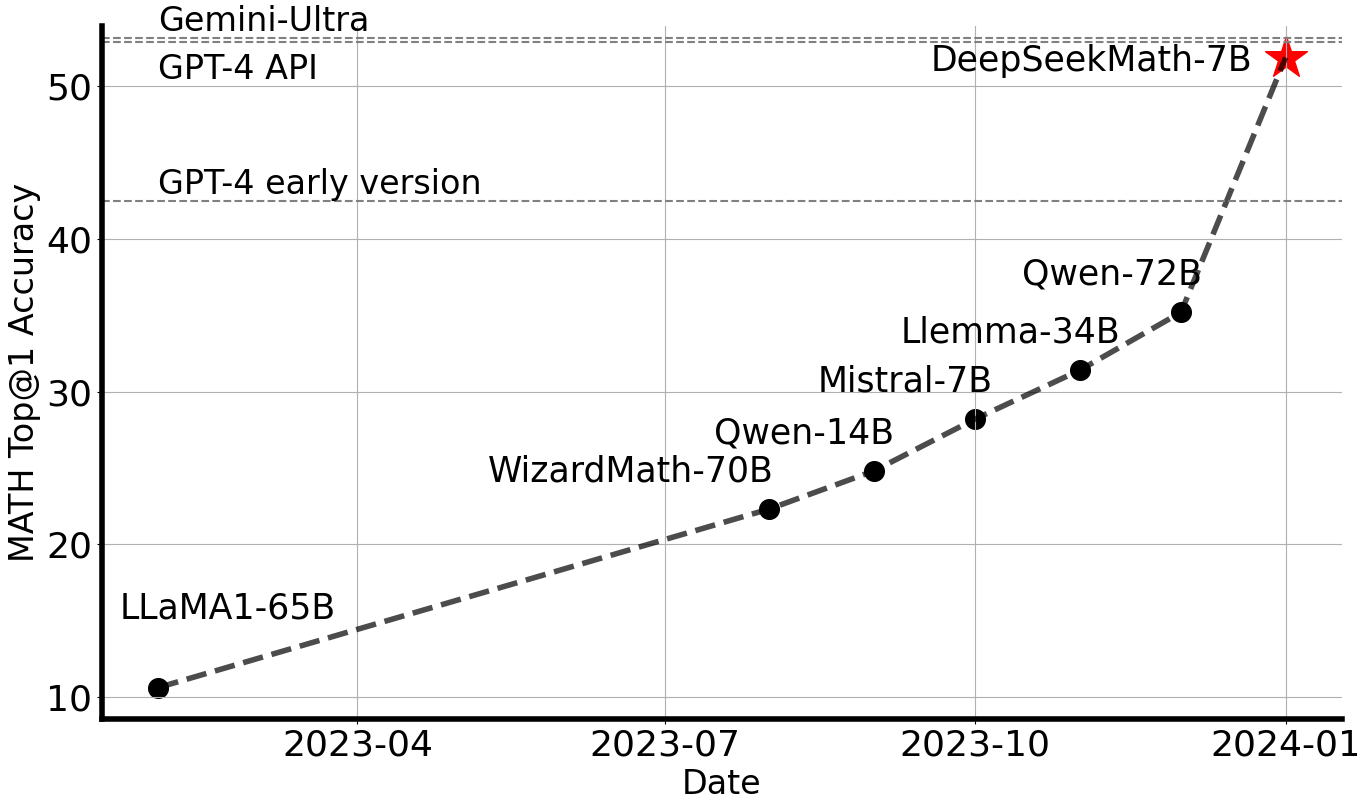
DeepSeek-Math 7B behaalt een indrukwekkende 51,7% op de competitieve MATH-benchmark , zonder afhankelijk te zijn van externe toolkits of stemtechnieken , en bereikt prestatieniveaus die vergelijkbaar zijn met Gemini Ultra en GPT-4.
Ter ondersteuning van onderzoek en ontwikkeling maken we controlepunten voor basis, instructie en reinforcement learning (RL)-modellen openbaar.
Evaluatieresultaten
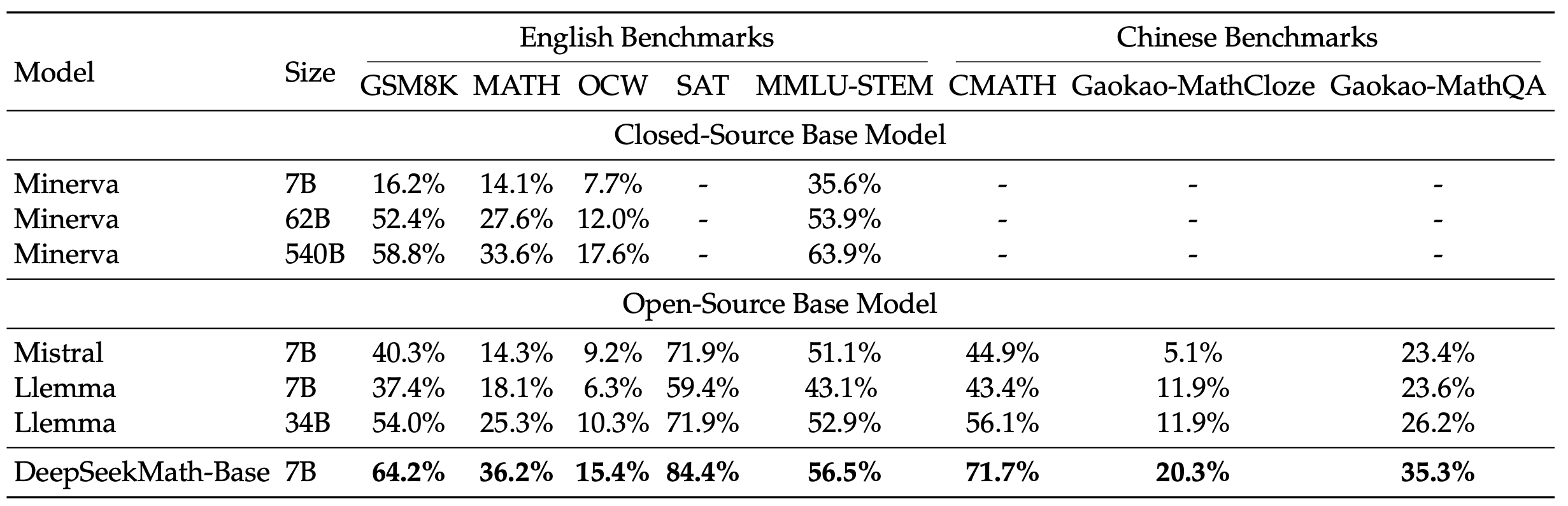
DeepSeekMath-Basis 7B
We hebben een uitgebreide evaluatie uitgevoerd van DeepSeek-Math-Base 7B , waarbij we de mogelijkheden ervan op het gebied van wiskundige probleemoplossing en meer hebben beoordeeld. Onze evaluatie richt zich op het vermogen van het model om:
- Genereer zelfstandige wiskundige oplossingen zonder afhankelijk te zijn van externe hulpmiddelen.
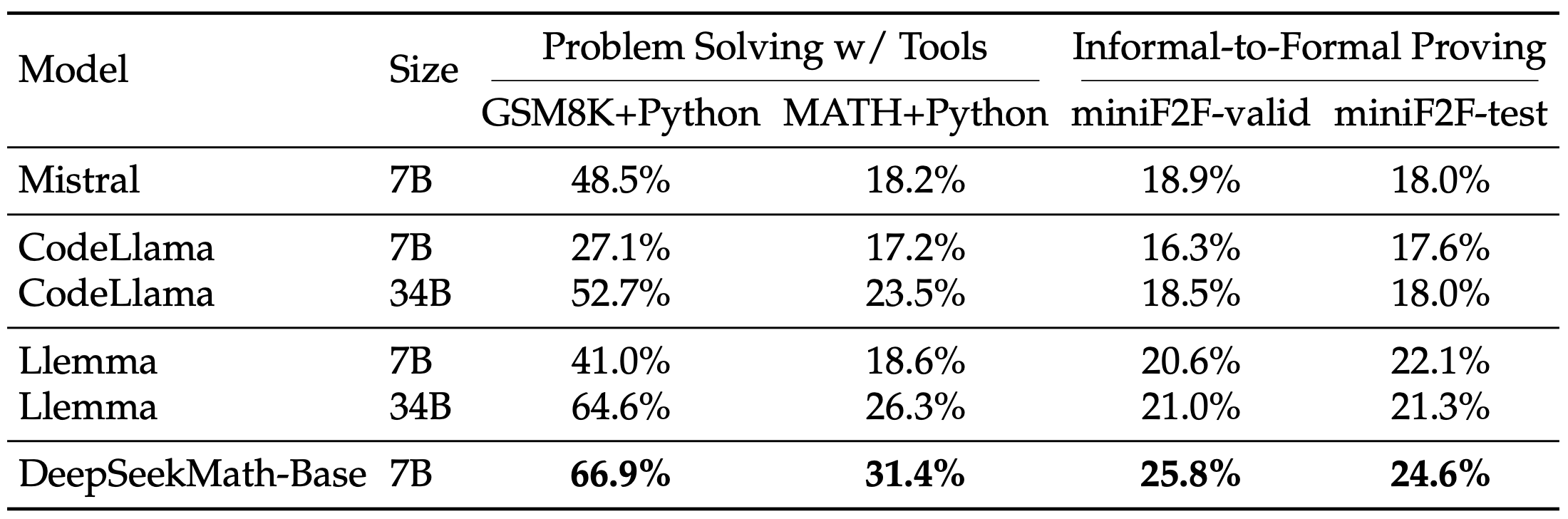
- Gebruik rekenhulpmiddelen om complexe wiskundige problemen efficiënt op te lossen.
- Voer formele stellingenbewijzen uit met behulp van gestructureerd logisch redeneren.
Naast wiskunde brengen we ook de bredere mogelijkheden van het model in kaart , waaronder het begrijpen van natuurlijke taal, logisch redeneren en programmeervaardigheden. Zo krijgen we een holistisch beeld van de algehele prestaties.
Wiskundige probleemoplossing met stapsgewijze redenering
Wiskundige probleemoplossing met gebruik van gereedschap
Begrip van natuurlijke taal, redeneren en code
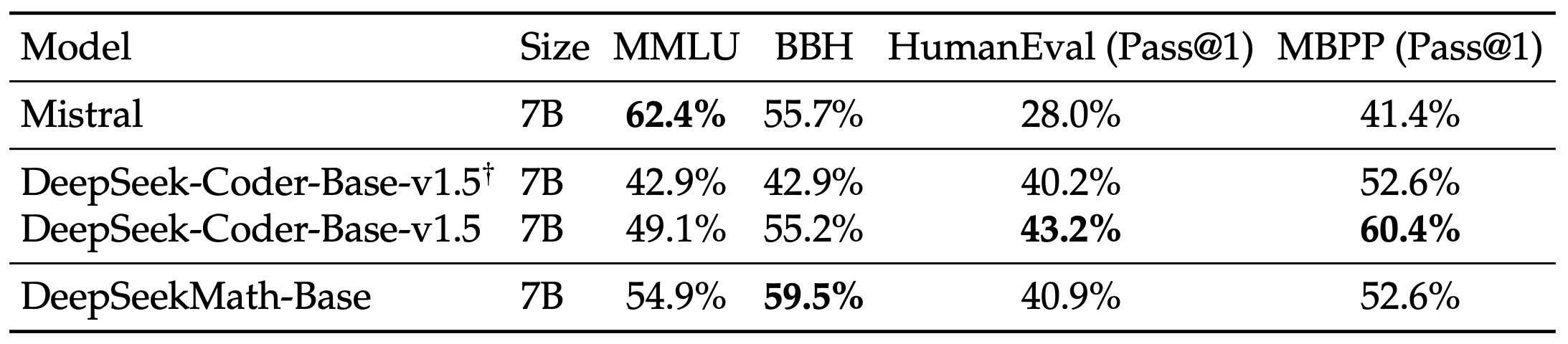
Belangrijkste bevindingen van de evaluatie:
- Superieure wiskundige redenering: DeepSeek-Math-Base 7B behaalt state-of-the-art prestaties op de competitieve MATH-dataset en overtreft bestaande open-source basismodellen met meer dan 10% door middel van een gedachteketen met weinig opnamen, en overtreft zelfs Minerva 540B.
- Geavanceerd gebruik van hulpmiddelen: door de voortdurende voortraining met DeepSeekCoder-Base-7B-v1.5 verbetert DeepSeekMath-Base 7B de mogelijkheid om wiskundige problemen op te lossen en te bewijzen door middel van programmatisch redeneren.
- Competitieve redeneer- en coderingsvaardigheden: het model demonstreert redeneer- en coderingsprestaties die vergelijkbaar zijn met DeepSeekCoder-Base-7B-v1.5 , waardoor het een veelzijdige oplossing is voor zowel wiskundige probleemoplossing als programmeertaken.
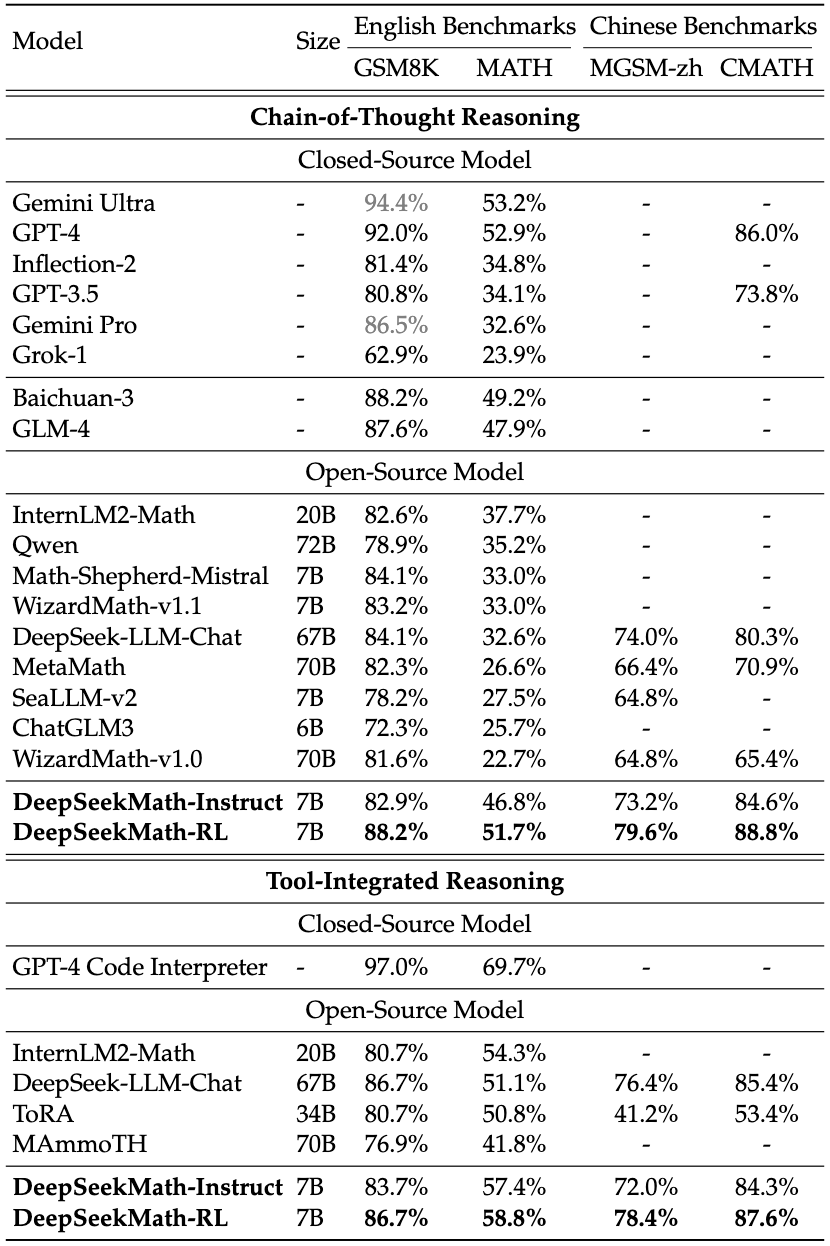
DeepSeekMath-Instruct en -RL 7B
DeepSeekMath-Instruct 7B is een wiskundig verfijnd model , gebouwd op DeepSeekMath-Base 7B , geoptimaliseerd voor gestructureerd stapsgewijs redeneren. DeepSeekMath-RL 7B verbetert deze mogelijkheden verder door te trainen op DeepSeekMath-Instruct 7B , waarbij gebruik wordt gemaakt van ons gepatenteerde Group Relative Policy Optimization (GRPO) -algoritme om zijn wiskundige redeneervaardigheden te verfijnen.
We beoordelen de wiskundige prestaties van het model in vier kwantitatieve redeneringsbenchmarks in zowel Engels als Chinees , waarbij we de mogelijkheden ervan evalueren met en zonder gebruik van tools . Zoals blijkt uit de resultaten, blinkt DeepSeekMath-Instruct 7B uit in gestructureerde, stapsgewijze probleemoplossing, terwijl DeepSeekMath-RL 7B een nauwkeurigheid van bijna 60% behaalt op de MATH-dataset met gebruik van tools, waarmee het alle bestaande open-sourcemodellen overtreft in wiskundige redenering.
Gegevensverzameling
Stap 1: Selecteer OpenWebMath , een zorgvuldig samengestelde verzameling van hoogwaardige wiskundige webteksten , als het eerste seedcorpus voor het trainen van een FastText- model.
Stap 2: Gebruik het getrainde FastText-model om wiskundige webpagina’s op te halen uit de gededupliceerde Common Crawl-database , waardoor een brede en diverse dataset ontstaat.
Stap 3: Voer statistische analyses uit om potentiële wiskundegerelateerde domeinen te identificeren , waardoor gerichtere en efficiëntere gegevensextractie mogelijk wordt.
Stap 4: Handmatig URL’s binnen de geïdentificeerde domeinen om hun koppeling met wiskundige inhoud te bevestigen en zo de nauwkeurigheid van de dataset te verbeteren.
Stap 5: Breid het seed corpus uit door gekoppelde webpagina’s op te nemen die nog niet eerder zijn verzameld. Dit proces wordt herhaald voor vier iteraties , waarbij de dataset in elke fase wordt verfijnd en verrijkt.
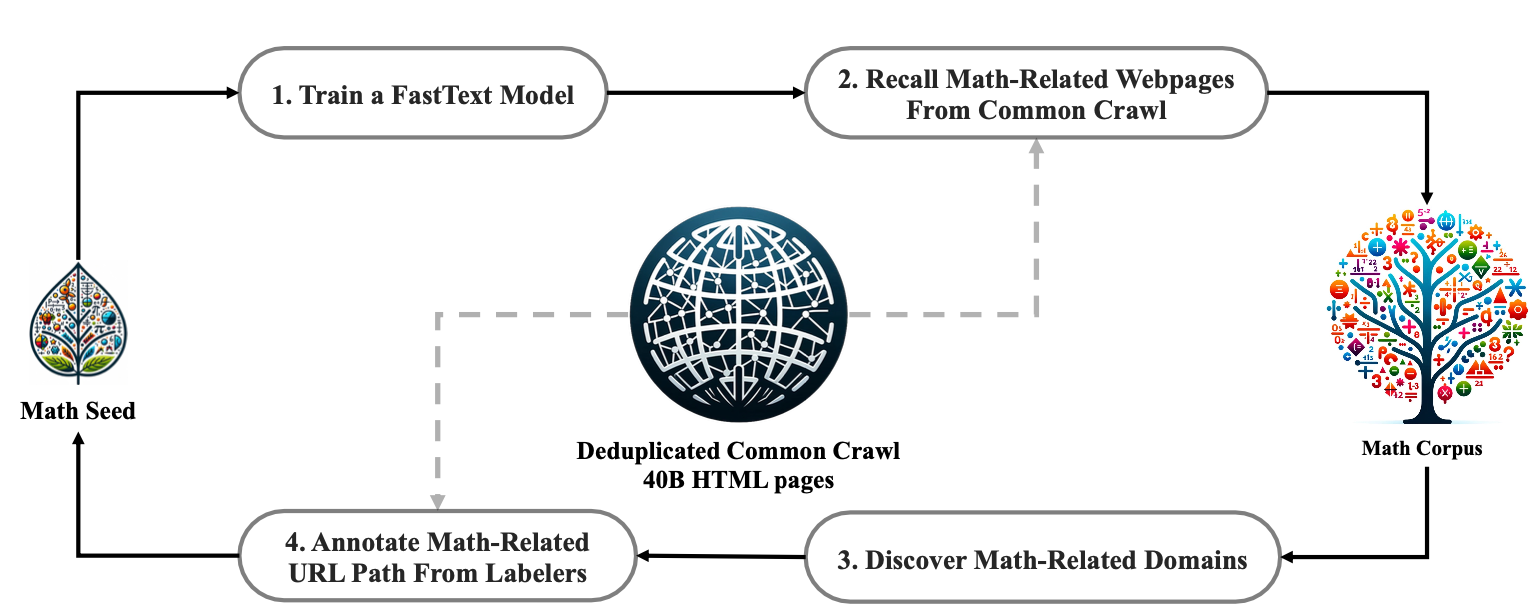
Na het voltooien van vier iteraties van dataverzameling, hebben we een dataset van hoge kwaliteit samengesteld die 35,5 miljoen wiskundige webpagina’s omvat , met in totaal 120 miljard tokens . Dit uitgebreide corpus verbetert het vermogen van het model om complexe wiskundige concepten met grotere nauwkeurigheid en diepte te verwerken en te beredeneren.
Model Downloads
We brengen DeepSeekMath 7B openbaar uit , inclusief de Base-, Instruct- en RL- varianten, ter ondersteuning van een breed scala aan academisch en commercieel onderzoek. Deze release is bedoeld om vooruitgang te boeken in wiskundig redeneren, probleemoplossing en AI-gestuurde berekeningen.
Houd er rekening mee dat het gebruik van het model onderhevig is aan de voorwaarden die zijn gespecificeerd in het gedeelte Licentie. Commercieel gebruik is toegestaan onder deze voorwaarden.
| Model | Sequentielengte | Download |
|---|---|---|
| DeepSeekMath-Base 7B | 4096 | 🤗 Hugging Face |
| DeepSeekMath-Instruct 7B | 4096 | 🤗 Hugging Face |
| DeepSeekMath-RL 7B | 4096 | 🤗 Hugging Face |
Contact
Als u vragen hebt of ondersteuning nodig hebt, kunt u een probleem melden in de DeepSeek-repository of rechtstreeks contact met ons opnemen via [email protected] op DeepSeekNederlands.nl – Bekijk hier de tutorial over het uitvoeren van het DeepSeek-Math-model!