Invoering
We introduceren DeepSeek-Coder-V2 , een open-source Mixture-of-Experts (MoE) codetaalmodel dat prestaties levert die vergelijkbaar zijn met GPT-4 Turbo in codespecifieke taken. DeepSeek-Coder-V2 is gebouwd op een tussenliggend controlepunt van DeepSeek-V2, met nog eens 6 biljoen tokens die worden gebruikt voor voortdurende pre-training. Deze extra training verbetert de coderings- en wiskundige redeneervaardigheden aanzienlijk , terwijl de sterke prestaties in algemene taaltaken behouden blijven.
Vergeleken met DeepSeek-Coder-33B toont DeepSeek-Coder-V2 significante verbeteringen op meerdere gebieden, waaronder codegerelateerde taken, redeneren en algemene mogelijkheden. Het breidt ook de ondersteuning van programmeertalen uit van 86 naar 338 talen en vergroot de contextlengte van 16K naar 128K , waardoor het veel grotere invoer en complexere projecten aankan.
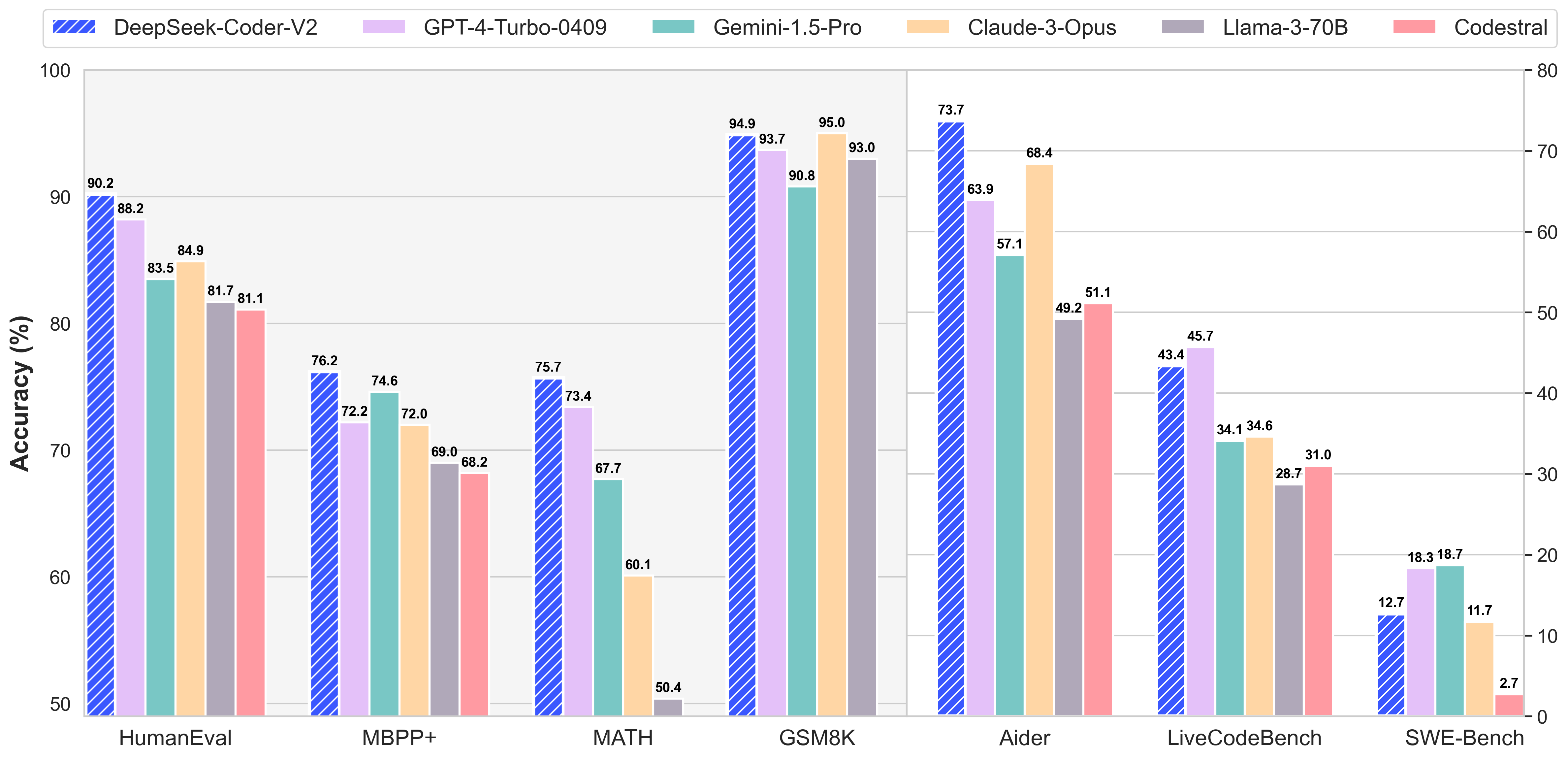
In standaard benchmarkevaluaties presteert DeepSeek-Coder-V2 beter dan verschillende closed-sourcemodellen, waaronder GPT-4 Turbo, Claude 3 Opus en Gemini 1.5 Pro, met name in benchmarks voor coderen en wiskunde. Hierdoor is het de beste keuze voor geavanceerde ontwikkel- en computertaken.
Model-downloads
We brengen DeepSeek-Coder-V2 uit in 16B en 236B parameterconfiguraties , gebouwd op het DeepSeek-MoE-framework. Ondanks hun grote schaal activeren deze modellen respectievelijk slechts 2,4B en 21B parameters tijdens inferentie, wat zorgt voor een hoge efficiëntie zonder dat dit ten koste gaat van de prestaties. Zowel basis- als instruct-tuned versies zijn beschikbaar voor het publiek, wat flexibele opties biedt voor een breed scala aan coderings- en redeneertaken.
| Model | #Totale Parameters | #Geactiveerde Parameters | Contextlengte | Download |
|---|---|---|---|---|
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Base | 236B | 21B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 128k | 🤗 HuggingFace |
Evaluatieresultaten
Codegeneratie
| #TP | #AP | MenselijkeEval | MBPP+ | LiveCodeBench | VSCO | |
|---|---|---|---|---|---|---|
| Gesloten-bronmodellen | ||||||
| Gemini-1.5-Pro | – | – | 83.5 | 74.6 | 34.1 | 4.9 |
| Claude-3-Opus | – | – | 84.2 | 72.0 | 34.6 | 7.8 |
| GPT-4-Turbo-1106 | – | – | 87.8 | 69.3 | 37.1 | 11.1 |
| GPT-4-Turbo-0409 | – | – | 88.2 | 72.2 | 45.7 | 12.3 |
| GPT-4o-0513 | – | – | 91.0 | 73.5 | 43.4 | 18.8 |
| Open-sourcemodellen | ||||||
| CodeStral | 22B | 22B | 78.1 | 68.2 | 31.0 | 4.6 |
| DeepSeek-Coder-Instrueren | 33B | 33B | 79.3 | 70.1 | 22.5 | 4.2 |
| Llama3-Instrueren | 70B | 70B | 81.1 | 68.8 | 28.7 | 3.3 |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 81.1 | 68.8 | 24.3 | 6.5 |
| DeepSeek-Coder-V2-Instrueren | 236B | 21B | 90.2 | 76.2 | 43.4 | 12.1 |
Code-aanvulling
| Model | #TP | #AP | RepoBench (Python) | RepoBench (Java) | MenselijkeEval FIM |
|---|---|---|---|---|---|
| CodeStral | 22B | 22B | 46.1 | 45.7 | 83.0 |
| DeepSeek-Coder-Base | 7B | 7B | 36.2 | 43.3 | 86.1 |
| DeepSeek-Coder-Base | 33B | 33B | 39.1 | 44.8 | 86.4 |
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 38.9 | 43.3 | 86.4 |
Code repareren
| #TP | #AP | Defects4J | SWE-Bench | Aider | |
|---|---|---|---|---|---|
| Gesloten-bronmodellen | |||||
| Gemini-1.5-Pro | – | – | 18.6 | 19.3 | 57.1 |
| Claude-3-Opus | – | – | 25.5 | 11.7 | 68.4 |
| GPT-4-Turbo-1106 | – | – | 22.8 | 22.7 | 65.4 |
| GPT-4-Turbo-0409 | – | – | 24.3 | 18.3 | 63.9 |
| GPT-4o-0513 | – | – | 26.1 | 26.7 | 72.9 |
| Open-sourcemodellen | |||||
| CodeStral | 22B | 22B | 17.8 | 2.7 | 51.1 |
| DeepSeek-Coder-Instruct | 33B | 33B | 11.3 | 0.0 | 54.5 |
| Llama3-Instruct | 70B | 70B | 16.2 | – | 49.2 |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 9.2 | 0.0 | 44.4 |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 21.0 | 12.7 | 73.7 |
Wiskundig redeneren
| #TP | #AP | GSM8K | MATH | AIME 2024 | Math Odyssey | |
|---|---|---|---|---|---|---|
| Gesloten-bronmodellen | ||||||
| Gemini-1.5-Pro | – | – | 90.8 | 67.7 | 2/30 | 45.0 |
| Claude-3-Opus | – | – | 95.0 | 60.1 | 2/30 | 40.6 |
| GPT-4-Turbo-1106 | – | – | 91.4 | 64.3 | 1/30 | 49.1 |
| GPT-4-Turbo-0409 | – | – | 93.7 | 73.4 | 3/30 | 46.8 |
| GPT-4o-0513 | – | – | 95.8 | 76.6 | 2/30 | 53.2 |
| Open-sourcemodellen | ||||||
| Llama3-Instruct | 70B | 70B | 93.0 | 50.4 | 1/30 | 27.9 |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 86.4 | 61.8 | 0/30 | 44.4 |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 94.9 | 75.7 | 4/30 | 53.7 |
Algemene natuurlijke taal
| Benchmark | Domein | DeepSeek-V2-Lite Chat | DeepSeek-Coder-V2-Lite Instruct | DeepSeek-V2 Chat | DeepSeek-Coder-V2 Instruct |
|---|---|---|---|---|---|
| BBH | Engels | 48.1 | 61.2 | 79.7 | 83.9 |
| MMLU | Engels | 55.7 | 60.1 | 78.1 | 79.2 |
| ARC-Easy | Engels | 86.1 | 88.9 | 98.1 | 97.4 |
| ARC-Challenge | Engels | 73.4 | 77.4 | 92.3 | 92.8 |
| TriviaQA | Engels | 65.2 | 59.5 | 86.7 | 82.3 |
| NaturalQuestions | Engels | 35.5 | 30.8 | 53.4 | 47.5 |
| AGIEval | Engels | 42.8 | 28.7 | 61.4 | 60 |
| CLUEWSC | Chinees | 80.0 | 76.5 | 89.9 | 85.9 |
| C-Eval | Chinees | 60.1 | 61.6 | 78.0 | 79.4 |
| CMMLU | Chinees | 62.5 | 62.7 | 81.6 | 80.9 |
| Arena-Hard | – | 11.4 | 38.1 | 41.6 | 65.0 |
| AlpaceEval 2.0 | – | 16.9 | 17.7 | 38.9 | 36.9 |
| MT-Bench | – | 7.37 | 7.81 | 8.97 | 8.77 |
| Alignbench | – | 6.02 | 6.83 | 7.91 | 7.84 |
Contextvenster
DeepSeek-Coder-V2 levert robuuste prestaties bij Needle In A Haystack (NIAH)-evaluaties en toont een consistente nauwkeurigheid over contextvensterlengtes tot 128K.
Chatwebsite
Gebruik DeepSeek-Coder-V2 rechtstreeks op het officiële platform coder.deepseek.com voor realtime-codeerondersteuning en geavanceerde taalmodelmogelijkheden.
API-Platform
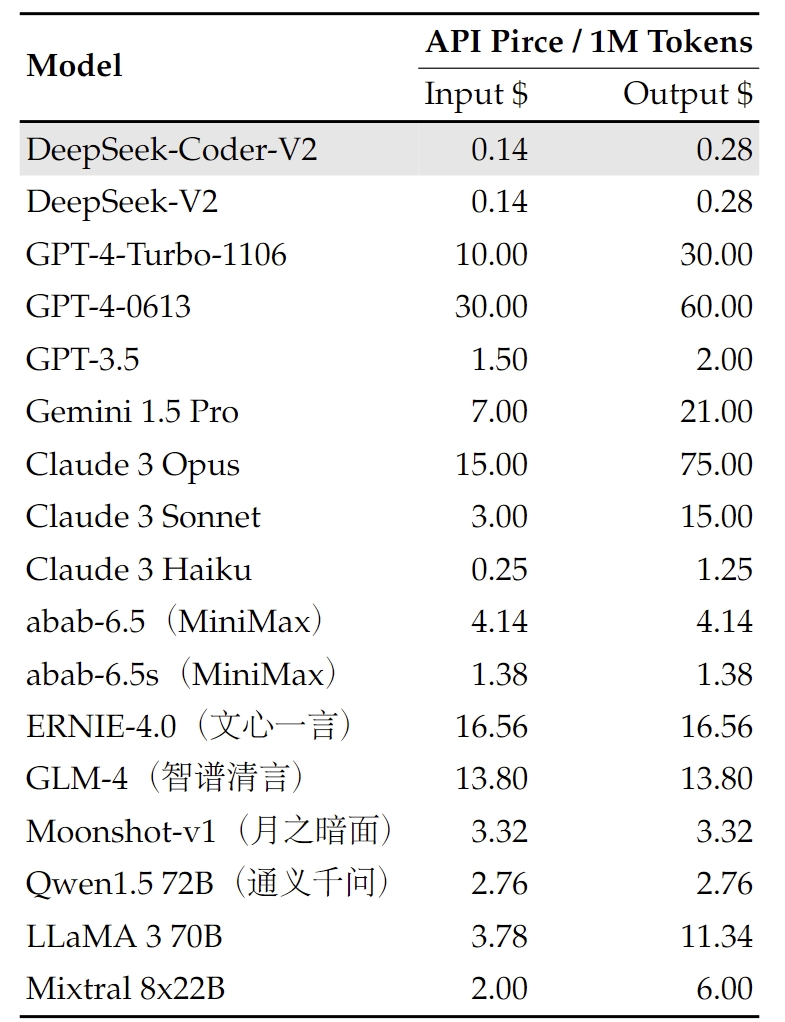
DeepSeek Platform biedt een OpenAI-compatibele API op platform.deepseek.com, wat naadloze integratie met uw applicaties mogelijk maakt. Profiteer van ons pay-as-you-go-prijsmodel voor uitzonderlijke waarde en kostenefficiëntie.
Contact
Als u vragen hebt of ondersteuning nodig hebt, kunt u een probleem melden in de DeepSeek-repository of rechtstreeks contact met ons opnemen via [email protected] op DeepSeekNederlands.nl – Bekijk hier de tutorial over het uitvoeren van het DeepSeek-Coder-V2-model!