Inleiding
We presenteren DeepSeek LLM, een geavanceerd taalmodel met 67 miljard parameters, dat vanaf nul nauwkeurig is getraind op een enorme dataset van 2 biljoen tokens in het Engels en Chinees. Ontworpen om AI-onderzoek te bevorderen, hebben we DeepSeek LLM 7B/67B Base en DeepSeek LLM 7B/67B Chat open source gemaakt , waarmee we de onderzoeksgemeenschap voorzien van state-of-the-art bronnen voor taalmodellering en AI-ontwikkeling.
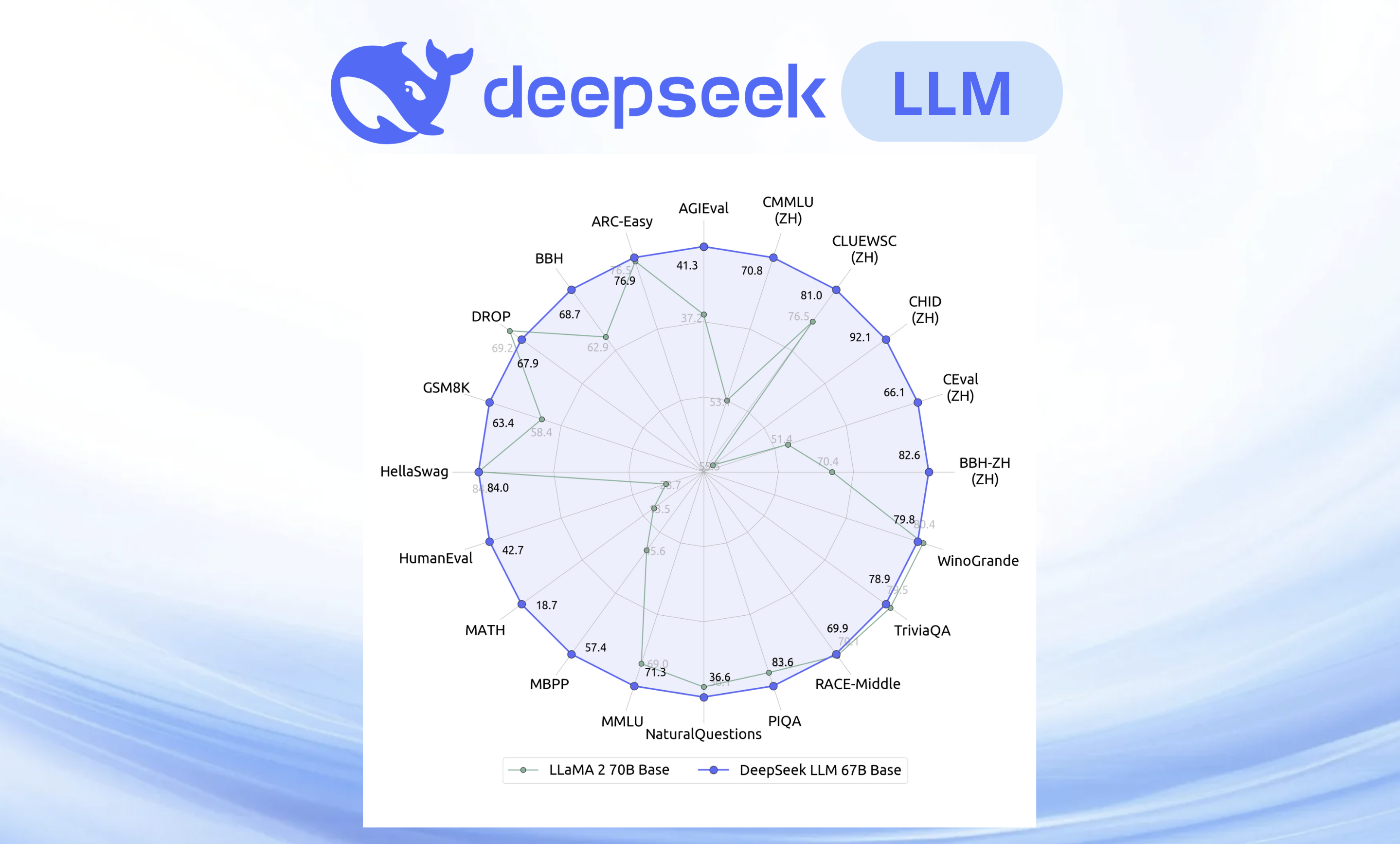
Superieure algemene vaardigheden
DeepSeek LLM 67B Base overtreft Llama 2 70B Base op het gebied van redeneren, coderen, wiskunde en begrip van de Chinese taal, waardoor het een van de meest veelzijdige open-sourcemodellen is die beschikbaar zijn.
Uitzonderlijke coderings- en wiskundige vaardigheden
DeepSeek LLM 67B Chat toont state-of-the-art prestaties in zowel codering als wiskunde , en behaalt:
- HumanEval-pas @ 1: 73,78
- GSM8K (0-opname): 84,1
- Wiskunde (0-shot): 32.6
Bovendien toont het opmerkelijke generalisatievaardigheden, met een indrukwekkende score van 65 op het Hongaarse nationale middelbare schoolexamen – een bewijs van de brede toepasbaarheid ervan.
Beheersing van de Chinese taal
Evaluaties geven aan dat DeepSeek LLM 67B Chat beter presteert dan GPT-3.5 op het gebied van Chinees begrip en generatie , wat de kracht ervan als toonaangevend meertalig model onderstreept.
Model Downloads
We brengen DeepSeek LLM 7B/67B openbaar uit , inclusief zowel Base als Chat-modellen, ter ondersteuning van een breed scala aan onderzoek in academische en commerciële domeinen. Om de transparantie verder te verbeteren en geavanceerde studie te vergemakkelijken, bieden we ook toegang tot tussenliggende controlepunten van het Base-model vanuit verschillende fasen van het trainingsproces.
Houd er rekening mee dat het gebruik van dit model wordt beheerst door de voorwaarden die zijn gespecificeerd in de sectie Licentie. Commercieel gebruik is toegestaan onder deze voorwaarden.
| Model | Sequentielengte | Download |
|---|---|---|
| DeepSeek LLM 7B Base | 4096 | 🤗 Hugging Face |
| DeepSeek LLM 7B Chat | 4096 | 🤗 Hugging Face |
| DeepSeek LLM 67B Base | 4096 | 🤗 Hugging Face |
| DeepSeek LLM 67B Chat | 4096 | 🤗 Hugging Face |
Evaluatieresultaten
Basismodel
We hebben een uitgebreide evaluatie van onze modellen uitgevoerd, naast belangrijke basismodellen, in een reeks representatieve benchmarks in zowel het Engels als het Chinees. Gedetailleerde resultaten zijn te vinden in de evaluatiemap.
De gerapporteerde evaluatieresultaten zijn afgeleid van ons interne, gepatenteerde hai-llm evaluatieframework , dat niet open source is . Houd er rekening mee dat bij het gebruik van de geconverteerde Hugging Face-modellen kleine discrepanties kunnen ontstaan vanwege verschillen in het framework.
| Model | HellaSwag 0-shot |
TriviaQA 5-shot |
MMLU 5-shot |
GSM8K 8-shot |
HumanEval 0-shot |
BBH 3-shot |
C-Eval 5-shot |
CMMLU 5-shot |
Chinese QA 5-shot |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA-2-7B | 75.6 | 63.8 | 45.8 | 15.5 | 14.6 | 38.5 | 33.9 | 32.6 | 21.5 |
| LLaMA-2-70B | 84.0 | 79.5 | 69.0 | 58.4 | 28.7 | 62.9 | 51.4 | 53.1 | 50.2 |
| DeepSeek LLM 7B Base | 75.4 | 59.7 | 48.2 | 17.4 | 26.2 | 39.5 | 45.0 | 47.2 | 78.0 |
| DeepSeek LLM 67B Base | 84.0 | 78.9 | 71.3 | 63.4 | 42.7 | 68.7 | 66.1 | 70.8 | 87.6 |
Chatmodel
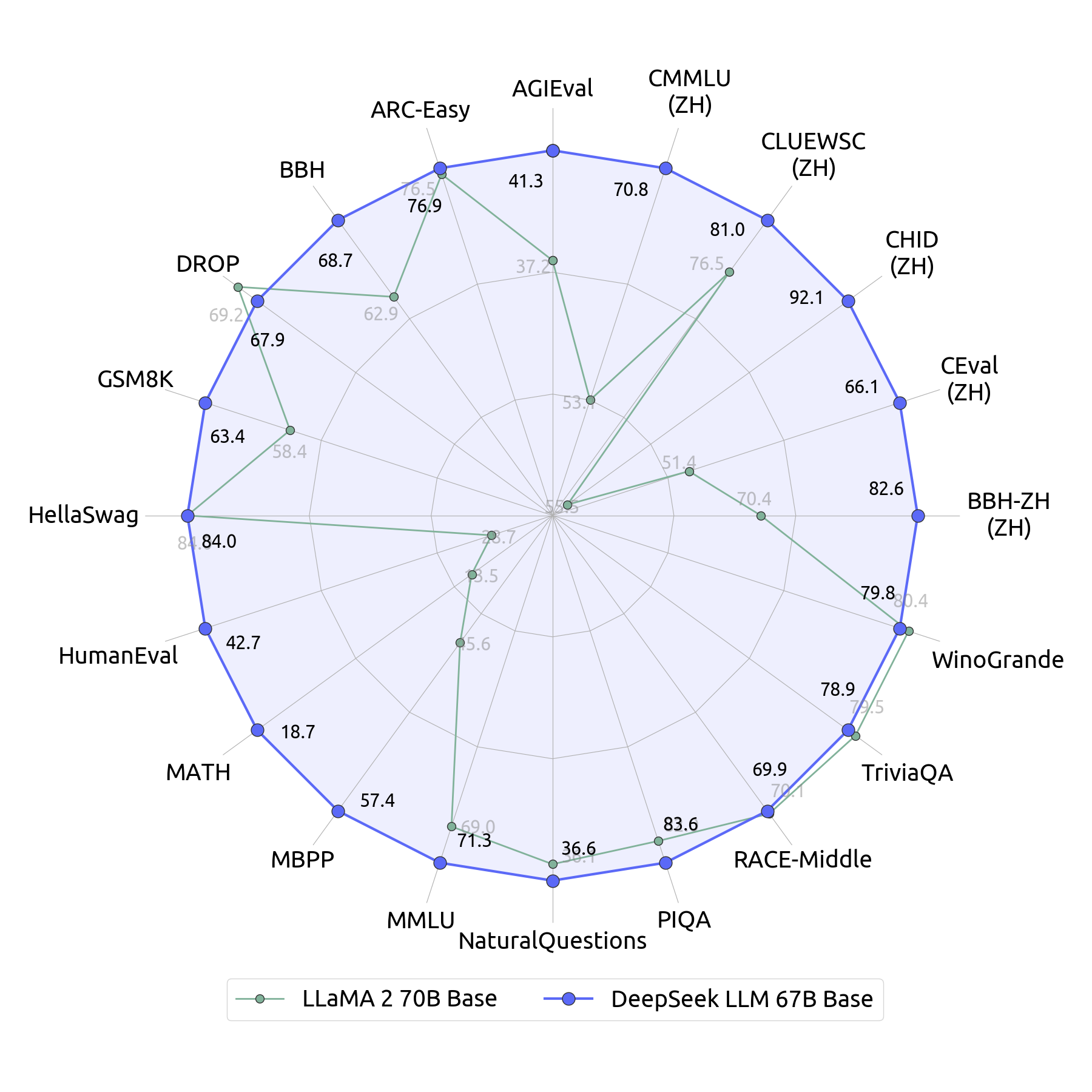
Nooit eerder gezien Examen
Om mogelijke dataverontreiniging te beperken en overfitting van testsets te voorkomen , hebben we nieuwe probleemsets ontwikkeld om de mogelijkheden van open-source LLM’s nauwkeurig te beoordelen.
Uit de evaluatieresultaten blijkt dat DeepSeek LLM 67B Chat uitzonderlijke prestaties levert bij deze nooit eerder vertoonde examens. Hiermee wordt aangetoond dat DeepSeek LLM 67B Chat effectief kan generaliseren voorbij de reeds bestaande benchmarks.
Hongaarse Nationale Middelbare School Examen
Volgens de methodologie die voor Grok-1 is gebruikt , hebben we de wiskundige mogelijkheden van ons model beoordeeld met behulp van het Hongaarse nationale middelbare schoolexamen. Dit examen bestaat uit 33 problemen , met scores bepaald door menselijke annotatie.
Om consistentie en nauwkeurigheid te garanderen, houden we ons aan de officiële scoremaatstaf die in de solution.pdf wordt beschreven en passen we hetzelfde evaluatiekader toe op alle modellen.
We hebben een fout in onze eerste evaluatie geïdentificeerd en gecorrigeerd . In deze herziene versie hebben we de laagste scores voor vragen 16, 17 en 18 weggelaten, evenals voor de eerder genoemde vraag op basis van afbeeldingen, om nauwkeurigheid en consistentie in onze beoordeling te garanderen.
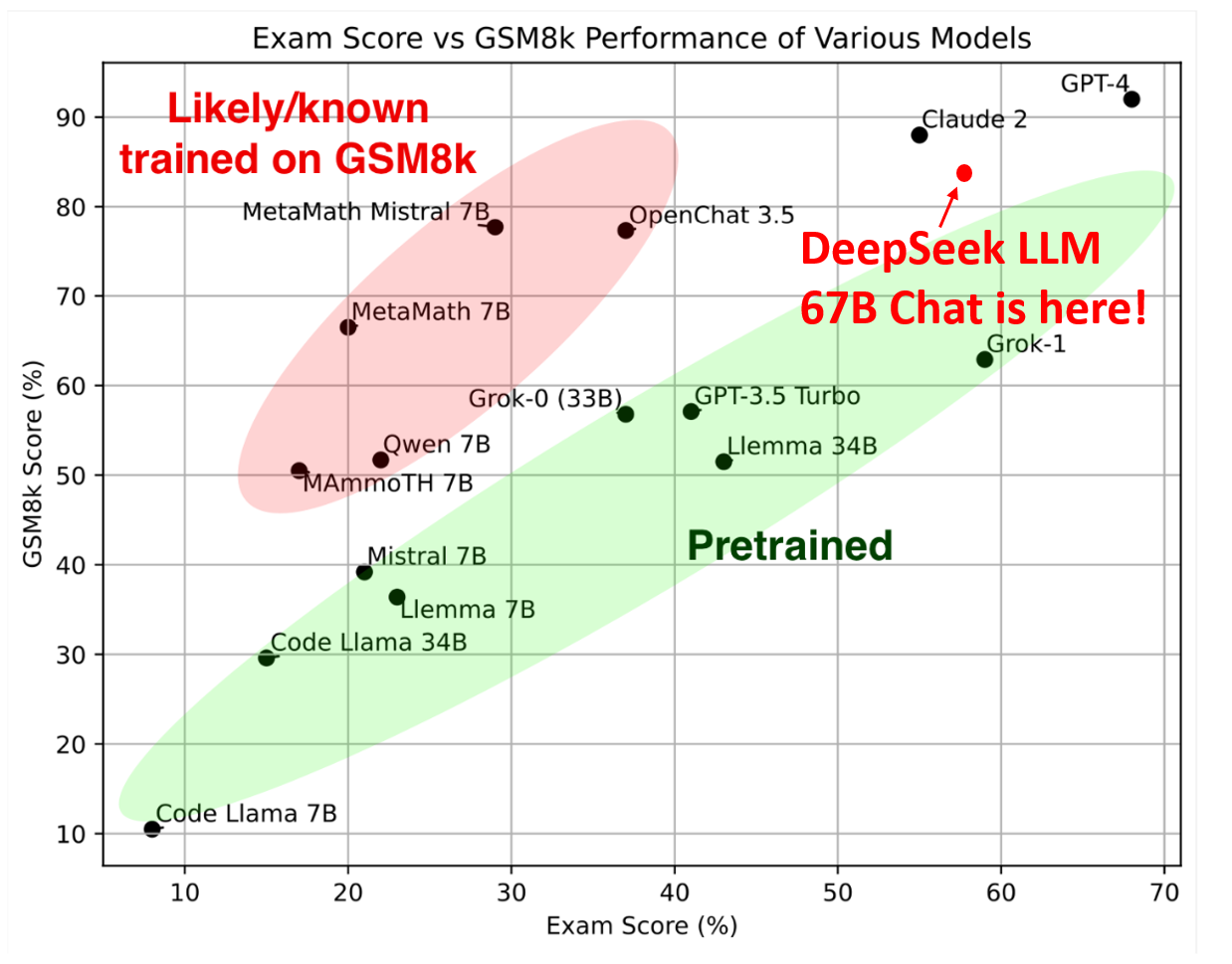
Instructie na evaluatie
Op 15 november 2023 bracht Google een instructie-volgende evaluatiedataset uit , ontworpen om het vermogen van taalmodellen om zich aan gestructureerde instructies te houden te beoordelen. Deze dataset categoriseert 25 verschillende typen verifieerbare instructies en omvat ongeveer 500 prompts , elk met een of meer verifieerbare instructies.
Voor onze evaluatie hebben we de prompt-level loose metric toegepast op alle modellen, waarbij we gebruik maakten van Google’s eerste vrijgegeven versie van de dataset. Voor evaluatieresultaten op basis van Google’s herziene testset , verwijzen we u naar de corresponderende figuren in ons artikel.
LeetCode wekelijkse wedstrijdevaluatie
Om de coderingsvaardigheden van ons model nauwkeurig te evalueren , hebben we gebruikgemaakt van problemen uit de LeetCode Weekly Contest , met name uit Weekly Contest 351-372 en Bi-Weekly Contest 108-117 , die de periode van juli 2023 tot en met november 2023 bestrijken.
Deze problemen werden verkregen via data crawling van LeetCode en bestaan uit 126 coding challenges , elk vergezeld door 20+ testcases . De evaluatiemethodologie weerspiegelt die van HumanEval , waarbij een model alleen als succesvol opgelost wordt beschouwd als de gegenereerde outputs alle testcases doorstaan.
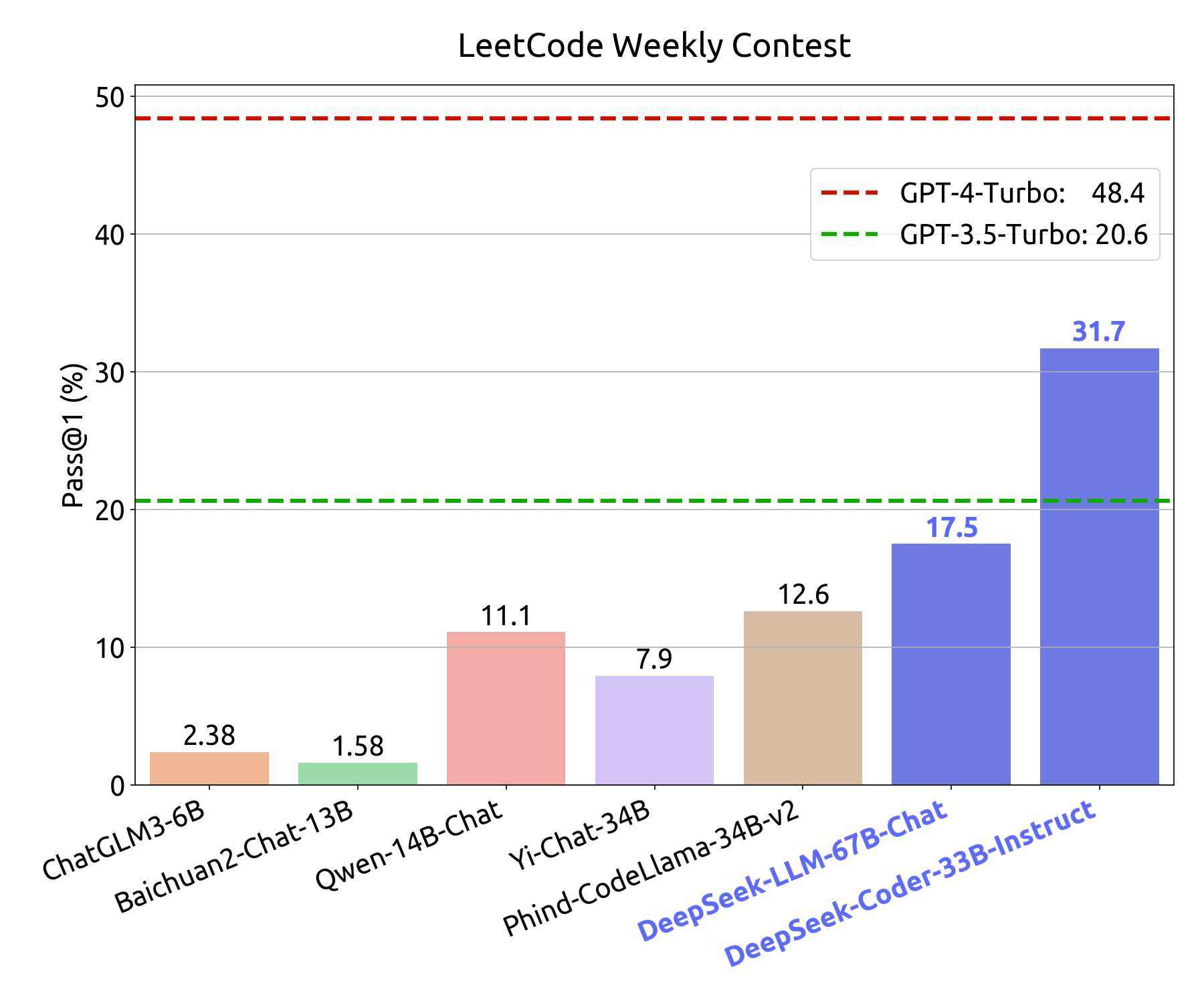
De coderingsprestaties van het model worden geïllustreerd in de onderstaande afbeelding:
- De y-as geeft de pass@1-score weer bij een menselijke evaluatietest binnen het domein.
- De x-as geeft de pass@1-score weer voor LeetCode Weekly Contest-problemen die buiten het domein vallen.
Dit evaluatiekader biedt een uitgebreide beoordeling van de mate waarin het model zowel zichtbare als onzichtbare programmeeruitdagingen aankan.
Standaard Benchmark
| Model | TriviaQA | MMLU | GSM8K | HumanEval | BBH | C-Eval | CMMLU | ChineseQA |
|---|---|---|---|---|---|---|---|---|
| DeepSeek LLM 7B Base | 59.7 | 48.2 | 17.4 | 26.2 | 39.5 | 45.0 | 47.2 | 78.0 |
| DeepSeek LLM 67B Base | 78.9 | 71.3 | 63.4 | 42.7 | 68.7 | 66.1 | 70.8 | 87.6 |
| DeepSeek LLM 7B Chat | 57.9 | 49.4 | 62.6 | 48.2 | 42.3 | 47.0 | 49.7 | 75.0 |
| DeepSeek LLM 67B Chat | 81.5 | 71.1 | 84.1 | 73.8 | 71.7 | 65.2 | 67.8 | 85.1 |
Herzie de benchmarks voor meerkeuzevragen
Onze experimentele bevindingen laten zien dat het verbeteren van prestaties op multiple-choice (MC) benchmarks zoals MMLU, CMMLU en C-Eval een relatief eenvoudige taak is . Door MC-vragen van Chinese examens op te nemen, zagen we een significante prestatieverbetering, zoals gedetailleerd in de onderstaande tabel.
| Model | MMLU | C-Eval | CMMLU |
|---|---|---|---|
| DeepSeek LLM 7B Chat | 49.4 | 47.0 | 49.7 |
| DeepSeek LLM 7B Chat + MC | 60.9 | 71.3 | 73.8 |
+MC staat voor de opname van 20 miljoen Chinese meerkeuzevragen afkomstig van het web. Om dataverontreiniging te voorkomen, hebben we deduplicatie uitgevoerd op de C-Eval-validatieset en de CMMLU-testset. Deze verbetering van de dataset verbetert niet alleen Chinese MC-benchmarks , maar verhoogt ook de Engelse benchmarkscores.
We hebben echter waargenomen dat MC-training de algemene kenniscapaciteiten van het model niet verbetert bij evaluaties die niet het multiple-choice-formaat volgen, met name in de 7B-modelsetting. Daarom hebben we ervoor gekozen om MC-gegevens niet te integreren in het pre-training of fine-tuningproces , omdat dit het risico zou opleveren van overfitting aan specifieke benchmarks in plaats van het bevorderen van verbeteringen van de algemene kennis.
Pre-trainingsdetails
Data
Ons primaire doel is om de diversiteit en kwaliteit van datasets holistisch te verrijken . Om dit te bereiken, hebben we meerdere optimalisatietechnieken ontwikkeld en geïntegreerd in onze datapijplijn. Centraal in deze inspanning staat “cc_cleaner”, een gedistribueerd batchverwerkingssysteem met frequente checkpointing , ontworpen om de verfijning van data te stroomlijnen en de efficiëntie van preprocessing te verbeteren.
Onze minimale levensvatbare oplossing (MVS) wijkt af van RefinedWeb + CCNet , waarbij we gebruikmaken van hun fundamentele inzichten en tegelijkertijd verder gaan dan dat. We waarderen hun waardevolle bijdragen aan AGI-onderzoek enorm.
Bovendien hebben we deterministische randomisatie in onze datapijplijn opgenomen , waardoor we de dataset continu kunnen verbeteren tijdens het uitgebreide en onvoorspelbare trainingsproces.
Onze trainingsdataset bestaat uit een diverse mix van:
- Internettekst
- Wiskundige inhoud
- Codeopslagplaatsen
- Boeken
- Zelf verzamelde gegevens (conform de robots.txt -richtlijnen)
We houden ons sterk aan privacy en auteursrechtbescherming . Alle persoonlijk identificeerbare informatie (PII) en auteursrechtelijk beperkte content worden strikt uit de dataset verwijderd om ethische AI-ontwikkeling te garanderen.Ons heuristisch filtersysteem gebruikt een combinatie van op regels gebaseerde technieken en ML-gestuurde modellen om trainingsdata te verfijnen. Dit pruningproces verwijdert webcontent van lage kwaliteit, terwijl waardevolle kennis met weinig middelen behouden blijft, de algehele kwaliteit van het corpus wordt verbeterd en schadelijke of giftige content wordt geëlimineerd.
We implementeren een rigoureus deduplicatieframework met MinhashLSH , waarmee we deduplicatie op document- en stringniveau garanderen. Deze aanpak elimineert redundanties en behoudt de uniciteit van de dataset, een kritische factor voor grootschalige trainingsstabiliteit en modelgeneralisatie.
Door deze technieken te integreren, zorgen we ervoor dat onze dataset van hoge kwaliteit blijft, ethisch verantwoord is verkregen en is geoptimaliseerd voor grootschalige AI-trainingen. Dit leidt uiteindelijk tot een robuuste en verantwoorde AI-ontwikkeling.
Pre-Training
Modelarchitectuur
DeepSeek LLM-modellen maken gebruik van dezelfde fundamentele architectuur als LLaMA , waarbij een autoregressieve transformatordecoder wordt gebruikt voor sequentiemodellering.
- Het 7B-model is uitgerust met Multi-Head Attention (MHA) , wat zorgt voor een efficiënt contextbegrip.
- Het 67B-model maakt gebruik van Grouped-Query Attention (GQA) om de geheugenefficiëntie en de inferentiesnelheid te optimaliseren.
Pre-trainingsdetails
DeepSeek LLM’s werden vooraf getraind op een enorme dataset van 2 biljoen tokens, waarbij gebruik werd gemaakt van:
- Sequentielengte: 4096 tokens
- Optimalisator: AdamW
Hyperparameters trainen
- Model 7B: Batchgrootte: 2304, Leersnelheid: 4,2e-4
- Model 67B: Batchgrootte: 4608, Leersnelheid: 3,2e-4
Er werd gebruikgemaakt van een leertempo-schema met meerdere stappen:
- 2000 warming-upstappen voor stabilisatie.
- De leercurve daalt tot 31,6% van het maximum bij 1,6 biljoen tokens.
- Verdere verlaging naar 10% van het maximum bij 1,8 biljoen tokens.
Om transparantie en inzicht in het trainingsproces te bieden, hebben we de trainingsverliescurve gepubliceerd, samen met benchmarkprestatiemetingen . Deze worden in de onderstaande secties gedetailleerd beschreven.
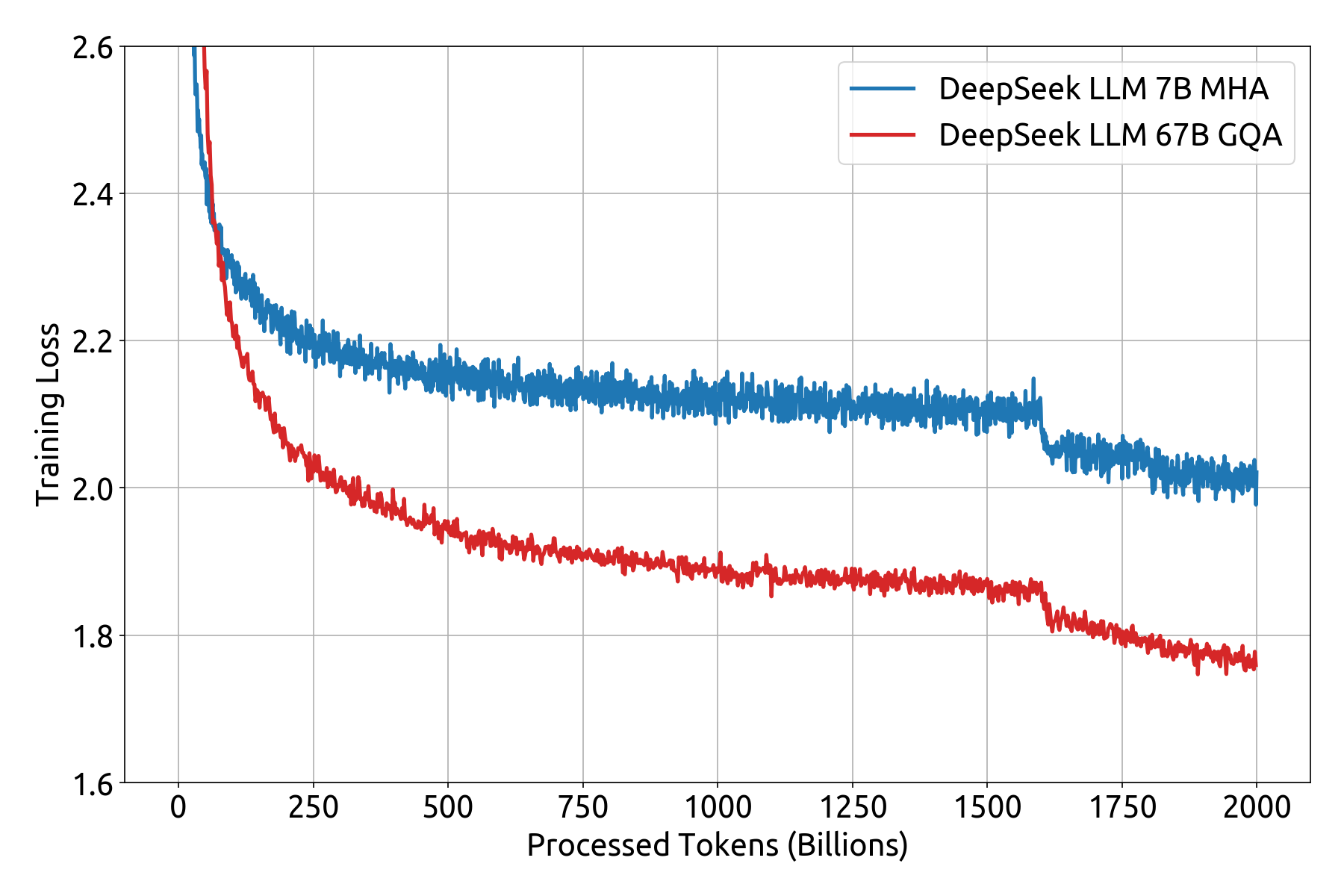
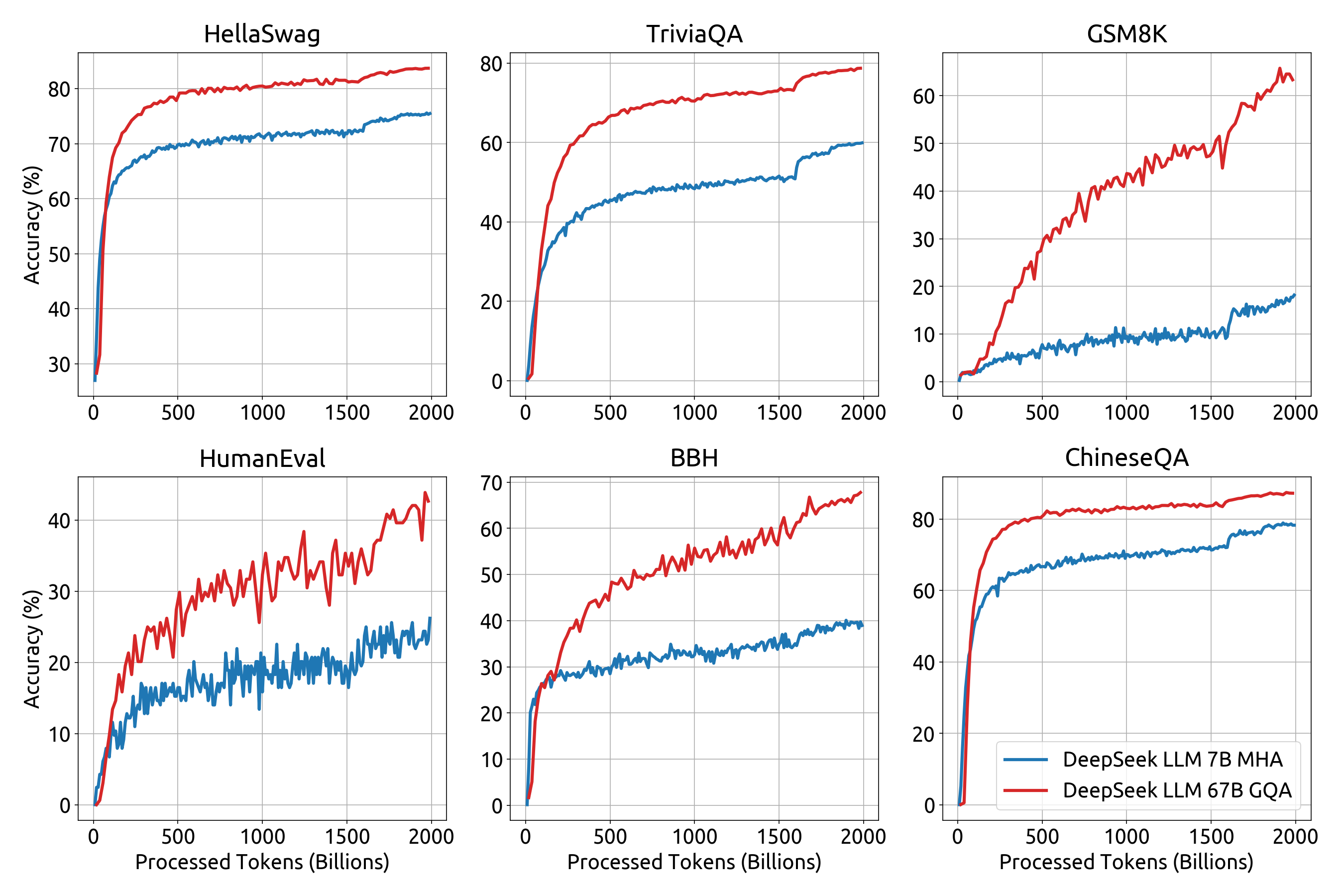
Beperkingen van DeepSeek-LLM
Hoewel DeepSeek-LLM opmerkelijke capaciteiten vertonen , zijn ze niet zonder inherente beperkingen . Hieronder staan de belangrijkste uitdagingen die gepaard gaan met dergelijke grootschalige taalmodellen:
1. Afhankelijkheid van trainingsgegevens en bias-voortplanting
DeepSeek-LLM worden getraind op enorme tekstcorpora, waardoor ze vatbaar zijn voor vooroordelen die inherent zijn aan de trainingsdata. Deze vooroordelen kunnen onbedoeld de modeluitvoer beïnvloeden, wat mogelijk leidt tot discriminerende of scheve reacties die maatschappelijke, culturele of taalkundige vooroordelen weerspiegelen die aanwezig zijn in de dataset.
2. Hallucinatie en feitelijk onjuiste uitkomsten
Ondanks hun geavanceerde redeneervermogen kunnen deze modellen soms reacties genereren die plausibel klinken, maar die feitelijk niet accuraat zijn. Dit fenomeen, bekend als hallucinatie, treedt op wanneer het model statistische patronen uit zijn trainingsdata overgeneraliseert zonder de reactie te baseren op kennis uit de echte wereld of geverifieerde bronnen .
3. Repetitieve outputgeneratie
Taalmodellen kunnen af en toe repetitief gedrag vertonen, zoals:
- Overbodige formuleringen of lusstructuren in antwoorden.
- Overmatig gebruik van bepaalde uitdrukkingen, waardoor de diversiteit van de output afneemt.
- Het genereren van uitgebreide maar semantisch vergelijkbare content, wat de leesbaarheid en betrokkenheid beïnvloedt.
Dit gebrek aan variatie kan soms de gebruikerservaring negatief beïnvloeden , vooral bij creatief schrijven of uitgebreide gesprekken waarbij originaliteit wordt verwacht.
Contact
Als u vragen hebt of ondersteuning nodig hebt, kunt u een probleem melden in de DeepSeek-repository of rechtstreeks contact met ons opnemen via [email protected] op DeepSeekNederlands.nl – Bekijk hier de tutorial over het uitvoeren van het DeepSeek-LLM-model!