Invoering
We presenteren onze eerste generatie redeneermodellen, DeepSeek-R1-Zero en DeepSeek-R1 , die zijn ontworpen om de grenzen van redeneervermogen te verleggen. DeepSeek-R1-Zero is getraind met behulp van grootschalige reinforcement learning (RL) zonder voorafgaande supervised fine-tuning (SFT), wat opmerkelijke emergente redeneergedragingen laat zien. Door RL ontwikkelde DeepSeek-R1-Zero op natuurlijke wijze krachtige redeneervermogens, waaronder multi-step probleemoplossing en logische gevolgtrekking.
DeepSeek-R1-Zero kent echter ook uitdagingen, zoals repetitieve output, verminderde leesbaarheid en incidentele taalvermenging . Om deze beperkingen aan te pakken en de redeneerprestaties verder te verbeteren, hebben we DeepSeek-R1 ontwikkeld , waarbij cold-startgegevens vóór de RL-fase zijn opgenomen. Deze verbetering resulteert in een stabieler en coherenter model dat prestaties levert die vergelijkbaar zijn met OpenAI-o1 in wiskunde-, coderings- en redeneertaken.
Ter ondersteuning van de onderzoeksgemeenschap hebben we DeepSeek-R1-Zero, DeepSeek-R1 en zes gedistilleerde dichte modellen afgeleid van DeepSeek-R1 op basis van LLaMA- en Qwen-architecturen open source gemaakt . Hiervan zet DeepSeek-R1-Distill-Qwen-32B een nieuwe standaard voor dichte modellen, presteert beter dan OpenAI-o1-mini in meerdere benchmarks en behaalt state-of-the-art resultaten.
Model Samenvatting
Na de training: grootschalige versterkingsleer op het basismodel
- In een baanbrekende aanpak passen we reinforcement learning (RL) direct toe op het basismodel zonder supervised fine-tuning (SFT) als voorlopige stap te gebruiken. Deze strategie stelt het model in staat om chain-of-thought (CoT) processen te verkennen voor het oplossen van complexe problemen, wat resulteert in de creatie van DeepSeek-R1-Zero . Het model demonstreert geavanceerde mogelijkheden zoals zelfverificatie, reflectie en het genereren van uitgebreide CoT’s , wat een belangrijke mijlpaal markeert voor de onderzoeksgemeenschap.
- Met name DeepSeek-R1-Zero is het eerste open onderzoek dat valideert dat LLM-redeneringsvermogens puur via RL kunnen worden gestimuleerd , zonder de noodzaak van SFT. Deze doorbraak zet een nieuwe richting uit voor toekomstige ontwikkelingen in redeneringsmodellen.
- Verder introduceren we de DeepSeek-R1-ontwikkelingspijplijn , die bestaat uit twee RL-fasen gericht op het ontdekken van verbeterde redeneringspatronen en het afstemmen daarvan op menselijke voorkeuren , evenals twee SFT-fasen die de kiem vormen voor zowel redenerings- als niet-redeneringsmogelijkheden. Deze pijplijn legt de basis voor het bouwen van geavanceerdere modellen die zowel de industrie als de onderzoeksgemeenschap ten goede zullen komen.
Destillatie: krachtige kleine modellen
- We laten zien dat de redeneringspatronen van grote modellen kunnen worden gedistilleerd tot kleinere modellen , waardoor betere prestaties worden behaald dan kleinere modellen die alleen via RL zijn getraind. Door gebruik te maken van de redeneringsgegevens die door DeepSeek-R1 zijn gegenereerd, hebben we meerdere dichte modellen , die veel worden gebruikt in onderzoek, verfijnd om hun redeneringsvermogen aanzienlijk te verbeteren.
- Onze evaluatieresultaten laten zien dat deze gedistilleerde kleinere dichte modellen uitblinken in verschillende benchmarks. Om de community te ondersteunen, hebben we gedistilleerde checkpoints open source gemaakt voor modellen met 1,5B, 7B, 8B, 14B, 32B en 70B parameters, gebaseerd op de Qwen2.5 en Llama3 series. Dit biedt onderzoekers en ontwikkelaars hoogwaardige modellen die efficiëntie en sterke prestaties combineren, wat de weg vrijmaakt voor toekomstige innovaties in redeneer- en distillatietechnieken.
Modeldownloads
DeepSeek-R1-modellen
| Model | #Totale Parameters | #Geactiveerde Parameters | Contextlengte | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K | 🤗 HuggingFace |
DeepSeek-R1-Zero en DeepSeek-R1 zijn gebouwd op de solide basis van DeepSeek-V3-Base, met geavanceerde aanpassingen gericht op redenering en keten-van-gedachten (CoT)-capaciteiten. Voor een gedetailleerd overzicht van de modelarchitectuur, raadpleeg de DeepSeek-V3 repository.
DeepSeek-R1-Distill-modellen
| Model | Basismodel | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Wiskunde-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Wiskunde-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
DeepSeek-R1-Distill-modellen zijn verfijnd op basis van open-source basismodellen, met behulp van voorbeelddata gegenereerd door DeepSeek-R1. Tijdens het fine-tuningproces hebben we de configuraties en tokenizers licht aangepast om optimale prestaties te garanderen. We raden aan om onze specifieke instellingen te gebruiken om deze modellen correct uit te voeren.
Evaluatieresultaten
DeepSeek-R1-evaluatie
Voor alle DeepSeek-modellen is de maximale generatielengte geconfigureerd op 32.768 tokens. Voor benchmarks met bemonstering hanteren we een temperatuur van 0,6 en een top-p-waarde van 0,95 . Om een robuuste evaluatie te garanderen, genereren we 64 antwoorden per query om de pass@1 -metriek nauwkeurig te schatten.
| Benchmark (Metriek) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|---|---|---|---|---|---|---|
| Architecture | – | – | MoE | – | – | MoE |
| # Geactiveerde Parameters | – | – | 37B | – | – | 37B |
| # Totale Parameters | – | – | 671B | – | – | 671B |
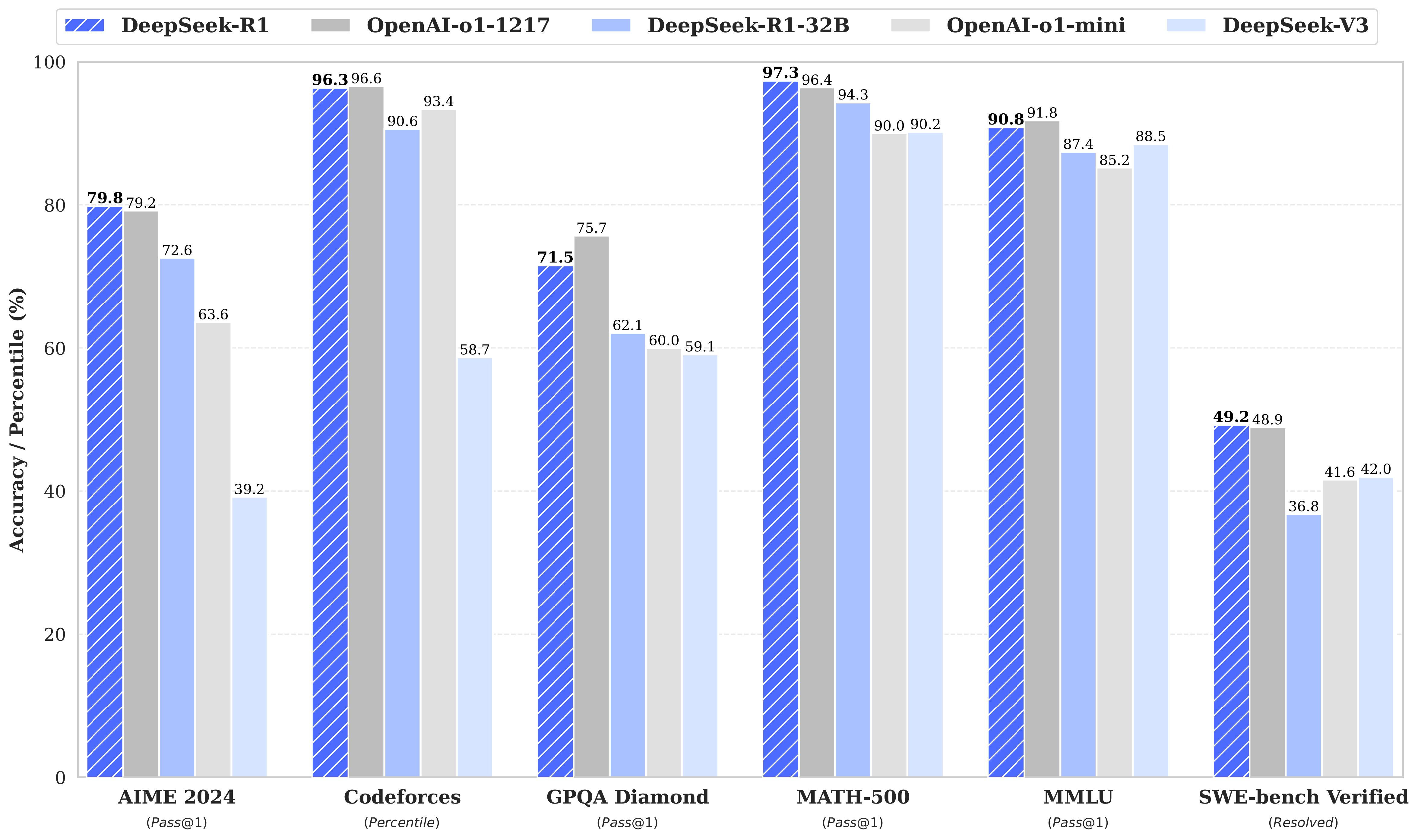
| MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | – | 92.9 |
| MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | – | 84.0 |
| DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 |
| IF-Eval (Prompt Strict) | 86.5 | 84.3 | 86.1 | 84.8 | – | 83.3 |
| GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 |
| SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | 47.0 | 30.1 |
| FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | – | 82.5 |
| AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | – | 87.6 |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | – | 92.3 |
| LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | – | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 |
| Codeforces (Rating) | 717 | 759 | 1134 | 1820 | 2061 | 2029 |
| SWE Verified (Resolved) | 50.8 | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
| Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | 61.7 | 53.3 |
| AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 |
| CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | – | 78.8 |
| CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | – | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | – | 91.8 |
| C-SimpleQA (Correct) | 55.4 | 58.7 | 68.0 | 40.3 | – | 63.7 |
Gedistilleerde modelevaluatie
| Model | AIME 2024 (Pass@1) | AIME 2024 (Cons@64) | MATH-500 (Pass@1) | GPQA Diamond (Pass@1) | LiveCodeBench (Pass@1) | CodeForces (Rating) |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
Chatwebsite en API-platform
Ervaar DeepSeek-R1 rechtstreeks op het officiële chatplatform op chat.deepseek.com . Schakel de ‘DeepThink’- modus in voor geavanceerd redeneren en verbeterde reacties.
Voor ontwikkelaars biedt het DeepSeek Platform een OpenAI-compatibele API voor naadloze integratie in uw applicaties. Ga naar platform.deepseek.com om te beginnen.
Contact
Voor vragen of ondersteuning kunt u gerust een probleem melden of direct contact met ons opnemen via [email protected]. Ons team staat klaar om u te helpen bij DeepSeekNederlands.nl. – Bekijk hier de tutorial over het uitvoeren van het DeepSeek-R1-model !