Introduceren
Vandaag introduceren we met trots DeepSeek-V2, een krachtig Mixture-of-Experts (MoE) taalmodel dat is ontworpen voor economische training en zeer efficiënte inferentie. Het model bevat 236B totale parameters , met 21B geactiveerd per token , wat superieure prestaties levert vergeleken met DeepSeek 67B terwijl de resources aanzienlijk worden geoptimaliseerd. DeepSeek-V2 verlaagt de trainingskosten met 42,5%, verkleint de KV-cachegrootte met 93,3% en verhoogt de maximale generatiedoorvoer met 5,76x.
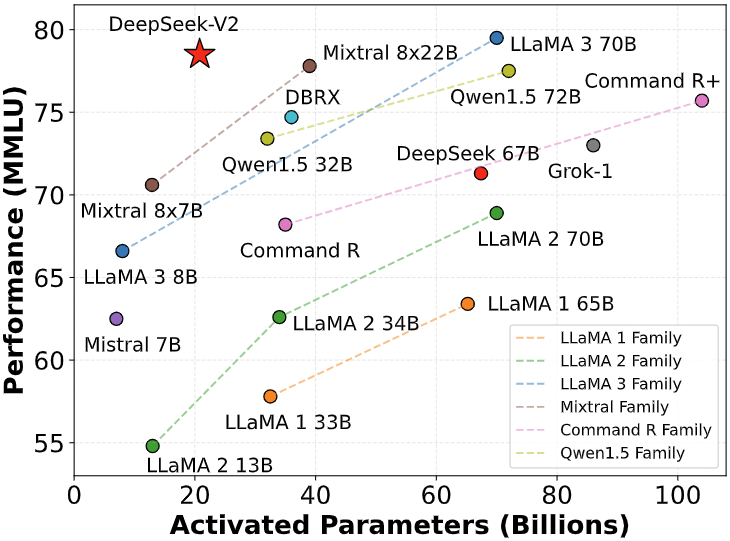
Vooraf getraind op een diverse, hoogwaardige dataset van 8,1 biljoen tokens, maakt DeepSeek-V2 gebruik van uitgebreide voortraining, gevolgd door Supervised Fine-Tuning (SFT) en Reinforcement Learning (RL) om zijn mogelijkheden te maximaliseren. Evaluatieresultaten tonen zijn uitzonderlijke prestaties op zowel standaard benchmarks als open-ended generation-taken, wat de effectiviteit van onze trainingsaanpak valideert.
Model Downloads
| Model | #Totale Parameters | #Geactiveerde Parameters | Contextlengte | Download |
|---|---|---|---|---|
| DeepSeek-V2-Lite | 16B | 2.4B | 32k | 🤗 Hugging Face |
| DeepSeek-V2-Lite-Chat (SFT) | 16B | 2.4B | 32k | 🤗 Hugging Face |
| DeepSeek-V2 | 236B | 21B | 128k | 🤗 Hugging Face |
| DeepSeek-V2-Chat (RL) | 236B | 21B | 128k | 🤗 Hugging Face |
Vanwege de huidige beperkingen op Hugging Face vertoont de open-source-implementatie tragere prestaties vergeleken met onze interne codebase bij uitvoering op GPU’s. Om optimale uitvoering te garanderen, bieden we een speciale vLLM-oplossing, die speciaal is ontworpen om de prestaties te verbeteren en de efficiëntie te maximaliseren voor het uitvoeren van ons model.
Evaluatieresultaten
Basismodel
Standaard Benchmark (Modellen groter dan 67B)
| Benchmark | Domein | LLaMA3 70B | Mixtral 8x22B | DeepSeek-V1 (Dense-67B) | DeepSeek-V2 (MoE-236B) |
|---|---|---|---|---|---|
| MMLU | Engels | 78.9 | 77.6 | 71.3 | 78.5 |
| BBH | Engels | 81.0 | 78.9 | 68.7 | 78.9 |
| C-Eval | Chinees | 67.5 | 58.6 | 66.1 | 81.7 |
| CMMLU | Chinees | 69.3 | 60.0 | 70.8 | 84.0 |
| HumanEval | Code | 48.2 | 53.1 | 45.1 | 48.8 |
| MBPP | Code | 68.6 | 64.2 | 57.4 | 66.6 |
| GSM8K | Wiskunde | 83.0 | 80.3 | 63.4 | 79.2 |
| Math | Wiskunde | 42.2 | 42.5 | 18.7 | 43.6 |
Standaard Benchmark (Modellen kleiner dan 16B)
| Benchmark | Domein | DeepSeek 7B (Dense) | DeepSeekMoE 16B | DeepSeek-V2-Lite (MoE-16B) |
|---|---|---|---|---|
| Architectuur | – | MHA+Dense | MHA+MoE | MLA+MoE |
| MMLU | Engels | 48.2 | 45.0 | 58.3 |
| BBH | Engels | 39.5 | 38.9 | 44.1 |
| C-Eval | Chinees | 45.0 | 40.6 | 60.3 |
| CMMLU | Chinees | 47.2 | 42.5 | 64.3 |
| HumanEval | Code | 26.2 | 26.8 | 29.9 |
| MBPP | Code | 39.0 | 39.2 | 43.2 |
| GSM8K | Wiskunde | 17.4 | 18.8 | 41.1 |
| Math | Wiskunde | 3.3 | 4.3 | 17.1 |
Voor uitgebreide evaluatiedetails, inclusief instellingen voor enkele opnamen en snelle configuraties, raadpleeg ons onderzoeksrapport.
Contextvenster
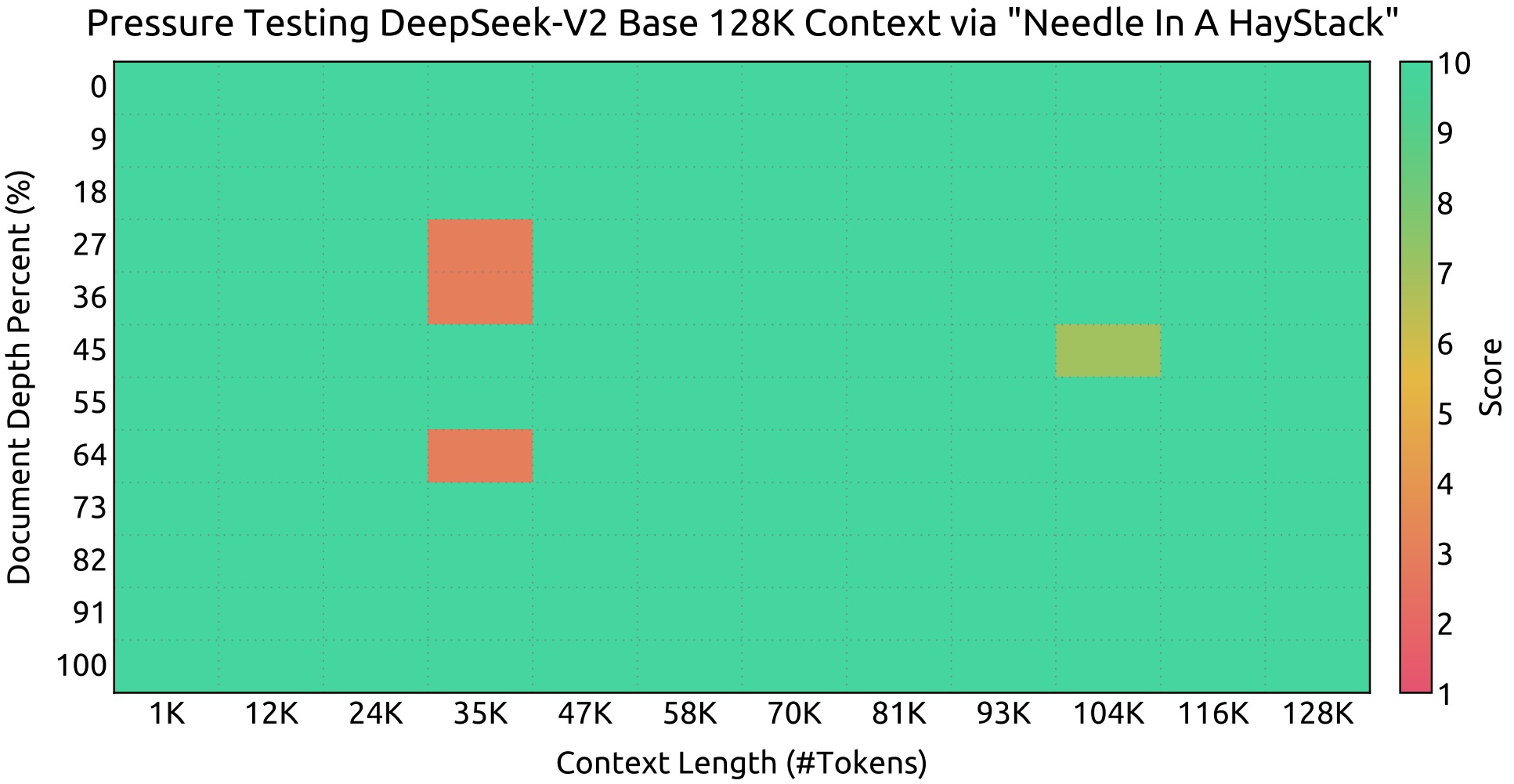
DeepSeek-V2 levert sterke prestaties bij Needle In A Haystack (NIAH)-evaluaties en behoudt een hoge nauwkeurigheid over alle contextvensterlengtes tot 128K.
Chatmodel
Standaard Benchmark (Modellen groter dan 67B)
| Benchmark | Domein | QWen1.5 72B Chat | Mixtral 8x22B | LLaMA3 70B Instruct | DeepSeek-V1 Chat (SFT) | DeepSeek-V2 Chat (SFT) | DeepSeek-V2 Chat (RL) |
|---|---|---|---|---|---|---|---|
| MMLU | Engels | 76.2 | 77.8 | 80.3 | 71.1 | 78.4 | 77.8 |
| BBH | Engels | 65.9 | 78.4 | 80.1 | 71.7 | 81.3 | 79.7 |
| C-Eval | Chinees | 82.2 | 60.0 | 67.9 | 65.2 | 80.9 | 78.0 |
| CMMLU | Chinees | 82.9 | 61.0 | 70.7 | 67.8 | 82.4 | 81.6 |
| HumanEval | Code | 68.9 | 75.0 | 76.2 | 73.8 | 76.8 | 81.1 |
| MBPP | Code | 52.2 | 64.4 | 69.8 | 61.4 | 70.4 | 72.0 |
| LiveCodeBench (0901-0401) | Code | 18.8 | 25.0 | 30.5 | 18.3 | 28.7 | 32.5 |
| GSM8K | Wiskunde | 81.9 | 87.9 | 93.2 | 84.1 | 90.8 | 92.2 |
| Math | Wiskunde | 40.6 | 49.8 | 48.5 | 32.6 | 52.7 | 53.9 |
Standard Benchmark (Models smaller than 16B)
| Benchmark | Domein | DeepSeek 7B Chat (SFT) | DeepSeekMoE 16B Chat (SFT) | DeepSeek-V2-Lite 16B Chat (SFT) |
|---|---|---|---|---|
| MMLU | Engels | 49.7 | 47.2 | 55.7 |
| BBH | Engels | 43.1 | 42.2 | 48.1 |
| C-Eval | Chinees | 44.7 | 40.0 | 60.1 |
| CMMLU | Chinees | 51.2 | 49.3 | 62.5 |
| HumanEval | Code | 45.1 | 45.7 | 57.3 |
| MBPP | Code | 39.0 | 46.2 | 45.8 |
| GSM8K | Wiskunde | 62.6 | 62.2 | 72.0 |
| Math | Wiskunde | 14.7 | 15.2 | 27.9 |
Engelse open-ended generatie-evaluatie
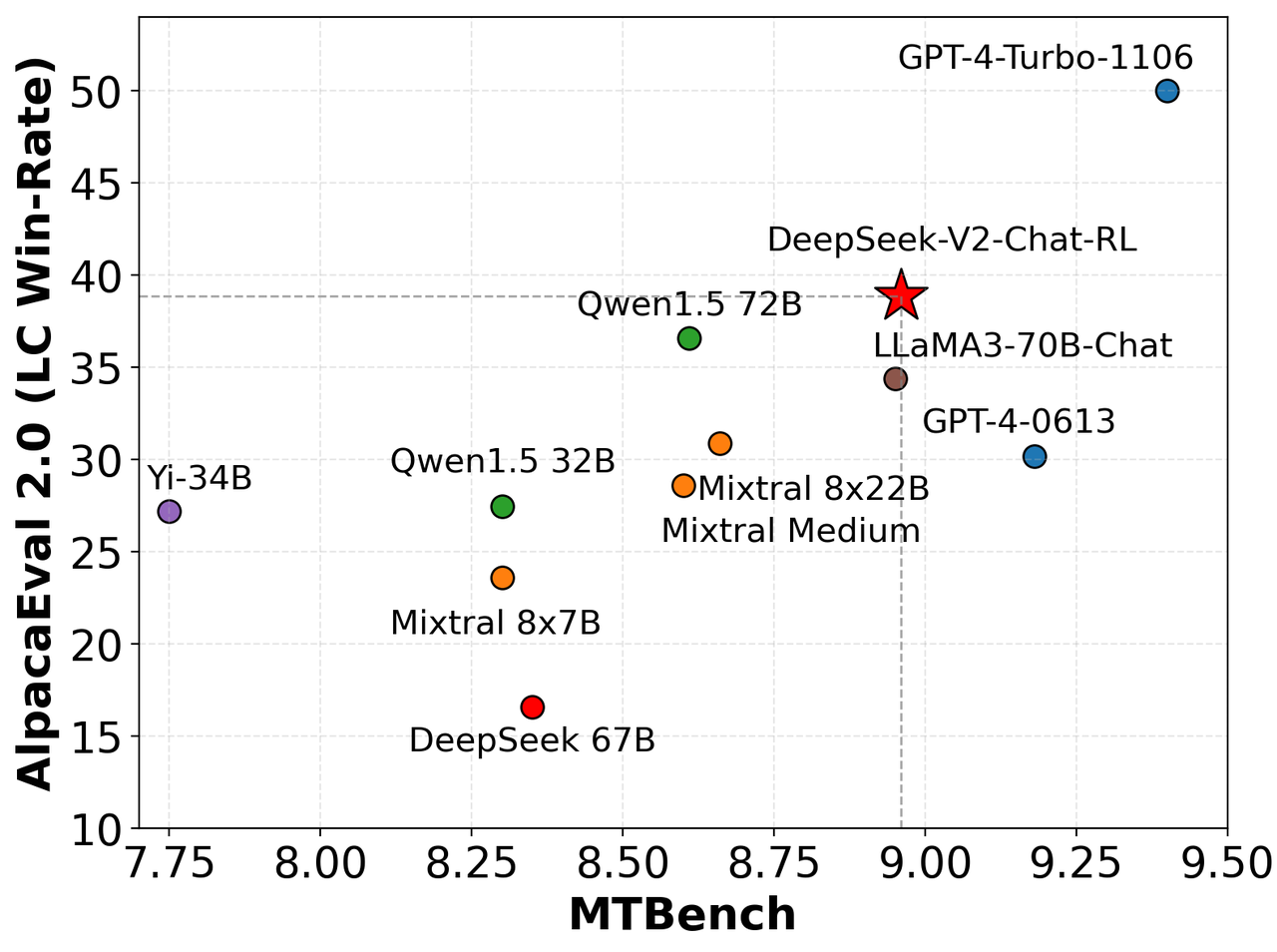
We hebben DeepSeek-V2-Chat-RL geëvalueerd op AlpacaEval 2.0 en MTBench , waarbij de concurrerende prestaties en de sterke mogelijkheden voor het genereren van hoogwaardige Engelstalige conversatiereacties werden aangetoond.
Chinese open-ended generatie-evaluatie
| 模型 | 开源/闭源 | 总分 | 中文推理 | 中文语言 |
|---|---|---|---|---|
| gpt-4-1106-preview | 闭源 | 8.01 | 7.73 | 8.29 |
| DeepSeek-V2 Chat (RL) | 开源 | 7.91 | 7.45 | 8.36 |
| erniebot-4.0-202404 (文心一言) | 闭源 | 7.89 | 7.61 | 8.17 |
| DeepSeek-V2 Chat (SFT) | 开源 | 7.74 | 7.30 | 8.17 |
| gpt-4-0613 | 闭源 | 7.53 | 7.47 | 7.59 |
| erniebot-4.0-202312 (文心一言) | 闭源 | 7.36 | 6.84 | 7.88 |
| moonshot-v1-32k-202404 (月之暗面) | 闭源 | 7.22 | 6.42 | 8.02 |
| Qwen1.5-72B-Chat (通义千问) | 开源 | 7.19 | 6.45 | 7.93 |
| DeepSeek-67B-Chat | 开源 | 6.43 | 5.75 | 7.11 |
| Yi-34B-Chat (零一万物) | 开源 | 6.12 | 4.86 | 7.38 |
| gpt-3.5-turbo-0613 | 闭源 | 6.08 | 5.35 | 6.71 |
| DeepSeek-V2-Lite 16B Chat | 开源 | 6.01 | 4.71 | 7.32 |
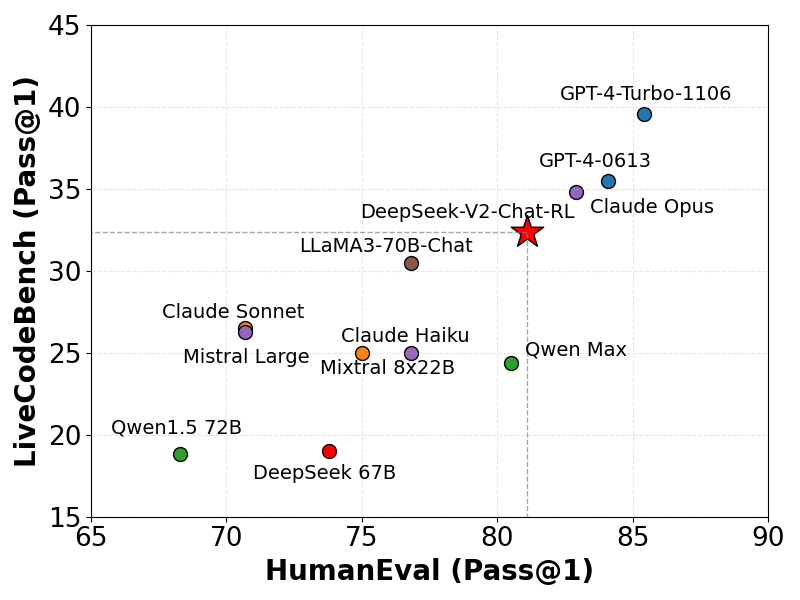
Coderingsbenchmarks
We hebben DeepSeek-V2 geëvalueerd op LiveCodeBench (0901-0401) , een benchmark die speciaal is ontworpen voor realtime coderingsuitdagingen. De resultaten tonen de aanzienlijke bekwaamheid van DeepSeek-V2 aan, met een Pass@1-score die verschillende geavanceerde modellen overtreft. Deze prestatie onderstreept de robuustheid en effectiviteit van het model bij het verwerken van complexe live coderingstaken met hoge nauwkeurigheid en betrouwbaarheid.
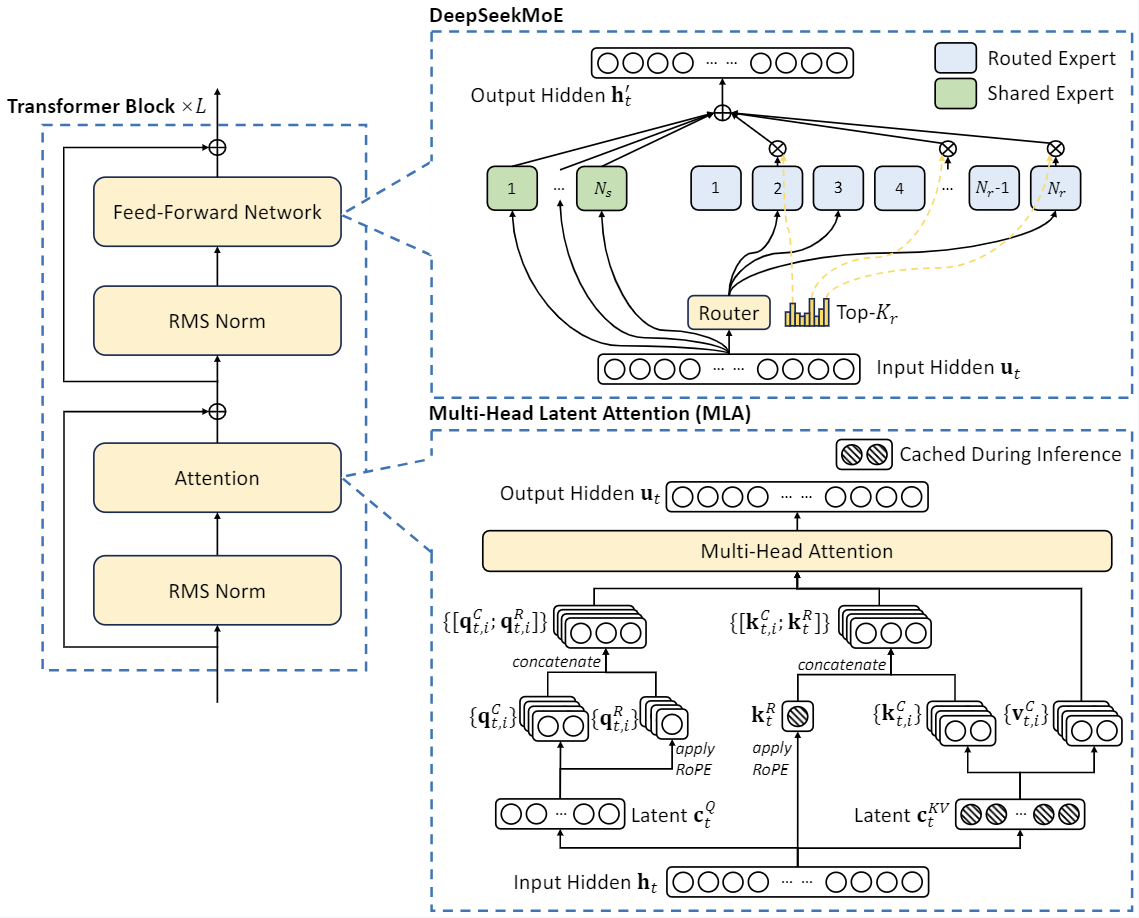
Modelarchitectuur
DeepSeek-V2 maakt gebruik van innovatieve architecturen om kosteneffectieve training en efficiënte inferentie te garanderen :
- Aandachtsmechanisme: We introduceren Multi-head Latent Attention (MLA) , dat gebruikmaakt van low-rank sleutel-waarde-uniecompressie om de knelpunten in de sleutel-waarde-cache tijdens de afleidingstijd te elimineren, wat de efficiëntie van de afleiding aanzienlijk verbetert.
- Feed-Forward Networks (FFN’s): DeepSeek-V2 maakt gebruik van de DeepSeekMoE -architectuur, een krachtig Mixture-of-Experts (MoE)-framework waarmee krachtigere modellen tegen lagere kosten kunnen worden getraind.
Chatwebsite
Communiceer rechtstreeks met DeepSeek-V2 op het officiële platform chat.deepseek.com voor realtimegesprekken en geavanceerde taalmodelmogelijkheden.
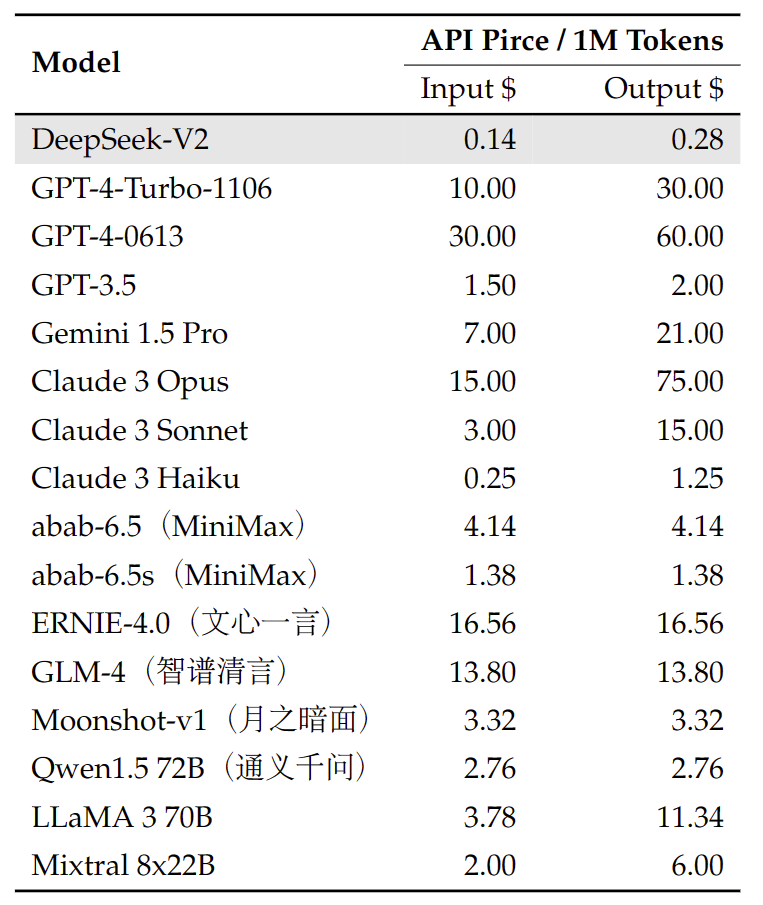
API-platform
We bieden een OpenAI-compatibele API op het DeepSeek-platform: platform.deepseek.com . Meld u nu aan om miljoenen gratis tokens te ontvangen en profiteer van onze pay-as-you-go -prijzen voor ongeëvenaarde waarde en flexibiliteit.
Contact
Voor vragen of ondersteuningsverzoeken kunt u gerust een probleem melden of contact met ons opnemen via [email protected]. Ons team staat voor u klaar bij DeepSeekNederlands.nl. – Bekijk hier de tutorial over het uitvoeren van het DeepSeek-V2-model !