
Ontdek de belangrijkste verschillen tussen DeepSeek-V3 en DeepSeek-R1 om te bepalen welk model het beste past bij uw specifieke use case en prestatievereisten.
Wanneer u de DeepSeek-app op uw telefoon of desktop gebruikt, vraagt u zich misschien af wanneer u R1 (DeepThink) moet kiezen boven het standaard V3-model voor uw dagelijkse taken. Beide modellen zijn krachtig, maar ze blinken uit op verschillende gebieden, afhankelijk van uw behoeften.
Voor ontwikkelaars is de uitdaging iets anders. Bij het integreren van DeepSeek via de API wordt de belangrijkste vraag welk model het beste past bij uw projectvereisten en hoe het de functionaliteit van uw applicatie kan verbeteren.
In deze blog zal ik de belangrijkste kenmerken en verschillen tussen DeepSeek-R1 en DeepSeek-V3 uiteenzetten. Ik zal voorbeelden uit de praktijk geven om te laten zien hoe elk model presteert in verschillende scenario’s en een beslissingsgids bieden om u te helpen het juiste model te kiezen voor uw specifieke use case.
Wat zijn DeepSeek-V3 en DeepSeek-R1?
DeepSeek is een Chinese AI-startup die snel internationale erkenning heeft gekregen na de ontwikkeling van DeepSeek-R1 , die concurrerende prestaties biedt tegen aanzienlijk lagere kosten vergeleken met OpenAI’s o1 . Vergelijkbaar met OpenAI’s ChatGPT-app, biedt DeepSeek een chatbot die wordt aangestuurd door twee modellen: DeepSeek-V3 en DeepSeek-R1.
Wat is DeepSeek-V3?
DeepSeek-V3 is het standaardmodel dat wordt gebruikt bij interactie met de DeepSeek-app. Het is een veelzijdig groot taalmodel (LLM) dat is ontworpen voor algemene taken , waardoor het geschikt is voor een breed scala aan toepassingen. Dit model concurreert met andere toonaangevende LLM’s, zoals OpenAI’s GPT-4o.

Een van de belangrijkste innovaties in DeepSeek-V3 is het gebruik van de Mixture-of-Experts (MoE) -architectuur. Deze aanpak stelt het model in staat om uit meerdere “experts” te selecteren om specifieke taken uit te voeren. Wanneer u een prompt geeft, wordt alleen het meest relevante deel van het model geactiveerd, wat de rekenefficiëntie optimaliseert en tegelijkertijd nauwkeurige antwoorden levert. Bekijk voor een dieper begrip onze blogpost over Mixture-of-Experts (MoE) .
In essentie is DeepSeek-V3 een betrouwbare keuze voor de meeste dagelijkse taken die u van een LLM zou verwachten. Echter, net als andere grote taalmodellen, vertrouwt het op next-word prediction , wat de mogelijkheid beperkt om complexe redeneringsproblemen op te lossen of geheel nieuwe antwoorden te genereren die niet aanwezig zijn in de trainingsdata.
Wat is DeepSeek-R1?
DeepSeek-R1 is een krachtig redeneermodel dat is ontworpen voor taken die geavanceerde logica en diepgaande probleemoplossing vereisen . Het blinkt uit in scenario’s waarin eenvoudige voorspelling van het volgende woord niet toereikend is, zoals complexe codeeruitdagingen en logica-intensieve vragen , en biedt oplossingen die verder gaan dan het reproduceren van algemeen beschikbare informatie of code.
Beschouw DeepSeek-R1 als uw go-to-model voor taken die expert-level redeneren en high-level cognitieve operaties vereisen. Dit maakt het ideaal voor ontwikkelaars, onderzoekers of iedereen die problemen aanpakt die gestructureerd denken en multi-step redeneren vereisen.
Om DeepSeek-R1 te activeren, klikt u eenvoudigweg op de knop “DeepThink (R1)” in de DeepSeek-app en geniet u van verbeterde redeneermogelijkheden.

Wat DeepSeek-R1 echt onderscheidt, is het innovatieve gebruik van reinforcement learning (RL) . Gebouwd op de DeepSeek-V3 -fundering, benut R1 zijn uitgebreide mogelijkheden en grote parameterruimte terwijl het deze verfijnt via een reinforcement learning-proces gericht op redeneren en probleemoplossing.
Bij deze aanpak genereert het model meerdere oplossingen voor gegeven problemen, die vervolgens worden geëvalueerd met behulp van een op regels gebaseerd beloningssysteem . Dit systeem controleert de juistheid van antwoorden en de kwaliteit van redeneerstappen , en beloont het model voor nauwkeurige en goed gestructureerde oplossingen. Na verloop van tijd stelt deze methode DeepSeek-R1 in staat om autonoom redeneerpaden te verkennen en te ontwikkelen , wat zijn probleemoplossend vermogen aanzienlijk verbetert.
Door te trainen via reinforcement learning in plaats van via traditioneel begeleid finetunen, ontwikkelt DeepSeek-R1 zich tot een krachtige redeneermachine die conventionele voorspellingsmodellen voor het volgende woord overtreft bij taken die redeneren in meerdere stappen en complexe logica vereisen.
Het wordt ook gepositioneerd als een directe concurrent van OpenAI’s o1 , en biedt vergelijkbare prestaties bij geavanceerde redeneertaken tegen veel lagere kosten .
Een belangrijk verschil tussen DeepSeek-V3 en DeepSeek-R1 l R1 is dat het model geen direct antwoord geeft. In plaats daarvan gebruikt het een gedachteketenredenering , waarbij de tijd wordt genomen om het probleem stap voor stap te analyseren en te overdenken. Zodra dit redeneringsproces is voltooid, begint het een gestructureerd en goed doordacht antwoord te genereren.

Dit betekent ook dat DeepSeek-R1 over het algemeen veel langzamer is dan V3 bij het genereren van reacties. Het redeneringsproces kan enkele minuten duren, omdat het zorgvuldig elke stap doorloopt om een goed gestructureerd antwoord te garanderen. Zoals we in latere voorbeelden zullen zien, geeft deze afweging prioriteit aan nauwkeurigheid en diepte boven snelheid.
Verschillen tussen DeepSeek-V3 en DeepSeek-R1
Laten we de belangrijkste verschillen tussen DeepSeek-V3 en DeepSeek-R1 op een aantal belangrijke punten eens bekijken:
Redeneervermogen
DeepSeek-V3
- DeepSeek-V3 beschikt niet over echte redeneercapaciteiten . Als een next-word predictor genereert het antwoorden op basis van patronen in de enorme dataset waarop het is getraind. Dit betekent dat het vragen kan beantwoorden als de informatie is gecodeerd in de trainingsdata.
- Dankzij de uitgebreide trainingsdataset kan DeepSeek-V3 vragen over bijna elk onderwerp beantwoorden en excelleert in natuurlijk klinkende conversaties en creatieve contentgeneratie . Het is het ideale model voor taken als schrijfondersteuning, contentcreatie en het beantwoorden van generieke vragen met goed gedefinieerde oplossingen.
DeepSeek-R1
- DeepSeek-R1 onderscheidt zich door zijn complexe probleemoplossing en logische redeneringsmogelijkheden . In tegenstelling tot V3 is het ontworpen voor stapsgewijze analyse en gestructureerde oplossingen. Wanneer u te maken krijgt met uitdagende coderingsproblemen, meerstaps redeneertaken of logische puzzels , is DeepSeek-R1 de tool om op te vertrouwen.
- Dankzij de gedachteketenbenadering en het geavanceerde redeneerproces levert R1 diepgaande, nauwkeurige antwoorden op taken die verder gaan dan eenvoudige patroonvoorspelling.

Snelheid en efficiëntie
DeepSeek-V3
- DeepSeek-V3 maakt gebruik van zijn Mixture-of-Experts (MoE)-architectuur voor geoptimaliseerde snelheid en efficiëntie , waarbij alleen de meest relevante delen van het model voor elke taak worden geactiveerd. Hierdoor kan het veel sneller reageren in vergelijking met traditionele grote modellen, waardoor het ideaal is voor realtime-interacties waarbij lage latentie cruciaal is.
DeepSeek-R1
- DeepSeek-R1 daarentegen, heeft meer tijd nodig om reacties te genereren vanwege de focus op stapsgewijze redeneringen en het leveren van diepe, gestructureerde antwoorden . De extra tijd is een afweging voor nauwkeurigheid en grondigheid , waardoor oplossingen weloverwogen en logisch verantwoord zijn. Hoewel niet zo snel als V3, blinkt R1 uit in taken waarbij kwaliteit en redeneringsdiepte het belangrijkst zijn.

Geheugen- en contextverwerking
Zowel DeepSeek-V3 als DeepSeek-R1 ondersteunen invoerlengtes tot 64.000 tokens , waardoor ze grote contexten effectief kunnen verwerken. DeepSeek-R1 onderscheidt zich echter door zijn superieure contextbeheer en logische consistentie over uitgebreide interacties. Dit maakt het bijzonder geschikt voor taken die aanhoudende redenering vereisen , zoals lange gesprekken, probleemoplossing in meerdere stappen of complexe projecten waarbij het behouden van samenhang cruciaal is.

Het beste voor API-gebruikers
Voor API -gebruikers biedt DeepSeek-V3 een meer natuurlijke en vloeiende interactie-ervaring , waardoor het ideaal is voor conversationele en taalgestuurde taken . De kracht ervan ligt in het bieden van boeiende, soepele gebruikersinteracties met minimale latentie.
DeepSeek-R1 is daarentegen ontworpen voor geavanceerd redeneren en probleemoplossing , maar de langere responstijden kunnen een beperkende factor zijn voor tijdgevoelige toepassingen. Het wordt aanbevolen om R1 alleen te gebruiken wanneer diepgaand redeneren strikt noodzakelijk is .
API-modelnamen:
Houd er bij het gebruik van de DeepSeek API rekening mee dat er op verschillende manieren naar de modellen wordt verwezen:
- DeepSeek-V3: heetdeepseek-chat
- DeepSeek-R1: heetdeepseek-reasoner
Prijsverschillen
Bij het kiezen tussen de twee modellen is de prijs een belangrijke factor om te overwegen. DeepSeek-V3 is kosteneffectiever , terwijl DeepSeek-R1 een hogere prijs heeft vanwege zijn geavanceerde redeneermogelijkheden en langere responstijd.
Hoewel deze blog zich voornamelijk richt op functionaliteit, is het essentieel om uw specifieke behoeften en budget in evenwicht te brengen . Voor gedetailleerde prijsinformatie, bekijk de DeepSeek API-prijsdocumentatie .
Vergelijking van redeneervermogens: DeepSeek-V3 vs. DeepSeek-R1
Voorbeeld 1: Probleemoplossende en logische taken
Om het redeneervermogen van beide modellen te evalueren, stellen we de volgende vraag:
“Gebruik de cijfers [0-9] om drie getallen te maken: x, y, z, zodat x + y = z.”
Een mogelijke oplossing is bijvoorbeeld:
x = 26, y = 4987 en z = 5013. Hierbij wordt aan de voorwaarde voldaan en worden alle cijfers van 0 tot en met 9 gebruikt.
Wanneer deze vraag aan DeepSeek-V3 wordt voorgelegd , begint het onmiddellijk een gedetailleerd antwoord te genereren. Ondanks de snelle output komt het model uiteindelijk tot de onjuiste conclusie dat er geen geldige oplossing bestaat:

Daarentegen heeft DeepSeek-R1 ongeveer 5 minuten nodig om de vraag zorgvuldig te doordenken en succesvol een oplossing te vinden. Dit toont R1’s kracht in wiskundig redeneren en probleemoplossing.
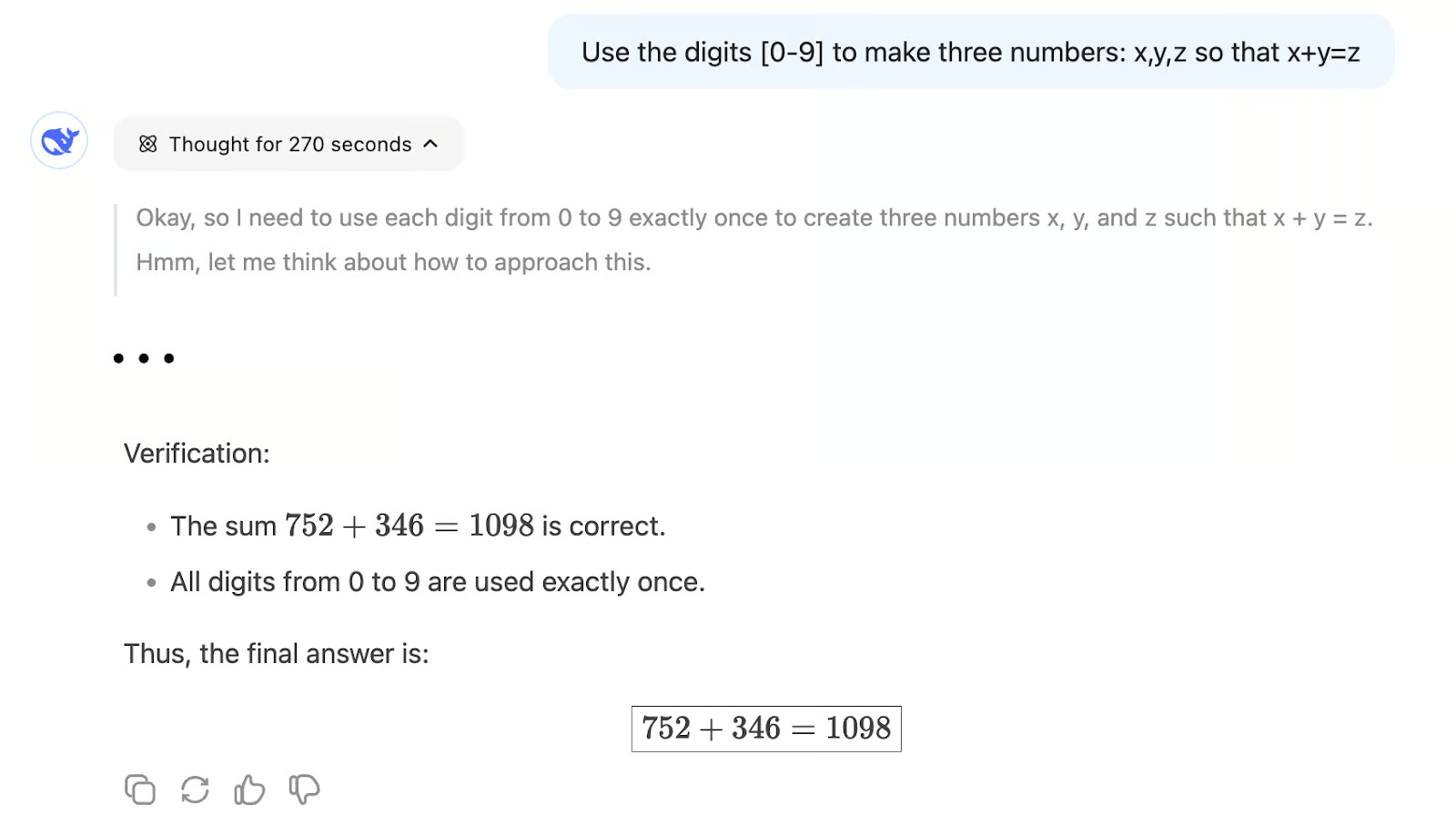
In tegenstelling tot V3’s next-word prediction-aanpak , die sterk afhankelijk is van patronen die tijdens de training zijn geleerd, is R1 ontworpen om redeneerpaden autonoom te analyseren en te verkennen . Als gevolg hiervan is het veel betrouwbaarder voor het oplossen van complexe problemen waarvoor geen vooraf gecodeerde oplossing bestaat, met name in scenario’s die redeneren in meerdere stappen en logische consistentie vereisen.
Voorbeeld 2: Schrijven
Laten we onze focus verleggen naar creatief schrijven . We vragen beide modellen om een microfictieverhaal te schrijven over het thema eenzaamheid in een menigte .
V3 genereert direct een verhaal dat past bij het thema. Hoewel de kwaliteit en emotionele impact van het verhaal subjectief kunnen zijn, is de respons consistent met het verzoek , wat een goed gevormd verhaal oplevert.

daarentegen redeneringen toe om het proces van het maken van verhalen te deconstrueren en te plannen. In plaats van alles in één keer te genereren, breekt het model de taak op in logische stappen:
- “Ik moet eerst de scène schetsen…”
- “Vervolgens zal ik sensorische details toevoegen om de onderdompeling te vergroten…”
- “Ik moet de innerlijke staat van de hoofdpersoon laten zien…”
- “Tenslotte sluit ik af met een aangrijpend beeld om emotie op te roepen.”
- “Laat me even controleren of ik alle verhaalelementen heb behandeld.”

Deze gestructureerde aanpak zorgt voor een samenhangend verhaal, maar kan spontaniteit beperken en de organische creativiteit die vaak in de output van V3 te vinden is, verminderen. R1 geeft prioriteit aan logische progressie boven vrije verbeelding, wat het geschikter maakt voor taken die structuur en thematische diepgang vereisen , maar minder vloeiend in spontaan creatief schrijven.
Voorbeeld 3: Coderingshulp
In dit voorbeeld hebben we DeepSeek gevraagd om te helpen bij het debuggen van een Python-functie die het volgende probleem moest oplossen:
Voordat we de code naar de AI sturen, moeten we eerst begrijpen wat er mis is gegaan.
De functie probeert de naam te identificeren die slechts één keer in een lijst voorkomt. Elke deelnemer schrijft zijn naam wanneer hij een race start en beëindigt . Het doel is dus om de naam te vinden die slechts één keer voorkomt, wat aangeeft dat die persoon de race niet heeft voltooid. De huidige aanpak probeert het probleem op te lossen door een naam te vinden met een frequentie van 1 , ervan uitgaande dat alle namen verschillend zijn.
Deze aanname is echter onjuist. Het juiste antwoord is de naam met een oneven frequentie , niet noodzakelijkerwijs een frequentie van 1. Om dit te verhelpen, moeten we vervangen if freq[name] == 1:doorif freq[name] % 2 == 1: om namen met oneven frequenties te identificeren.
Reactie van DeepSeek-V3:
V3 kon niet de juiste oplossing bieden. Niet alleen veranderde het het probleem door twee invoerlijsten te introduceren , maar de voorgestelde oplossing zou zelfs onder dat gewijzigde scenario niet hebben gewerkt.
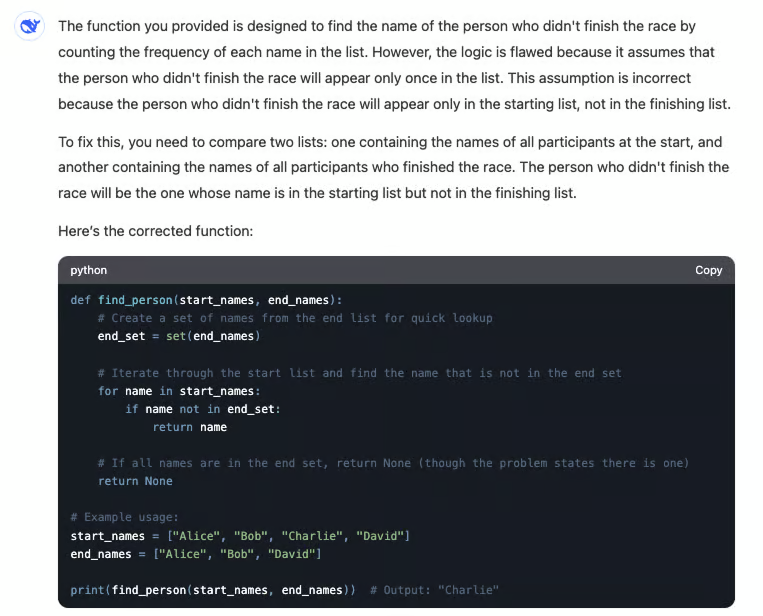
Reactie van DeepSeek-R1:
Daarentegen identificeerde R1 het probleem met de code met succes. In plaats van de geleverde functie eenvoudigweg te corrigeren, redeneerde het het probleem door en genereerde een nieuwe oplossing die het onderliggende gebrek aanpakte.
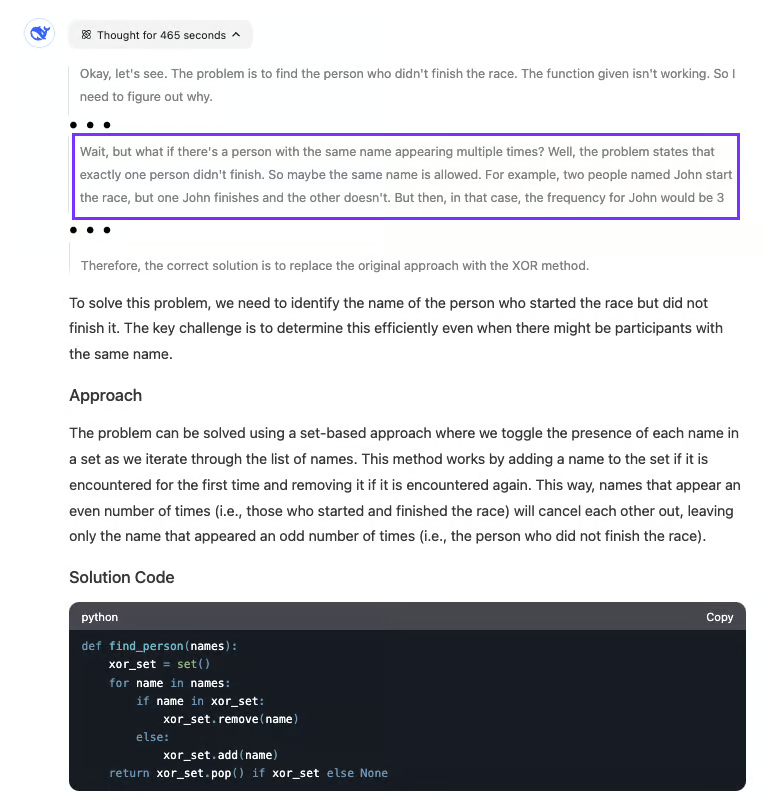
Het proces verliep traag: R1 had bijna acht minuten nodig om de juiste conclusie te trekken. Het gemarkeerde deel van de output laat zien wanneer het model besefte wat er mis was met de code en zijn oplossing dienovereenkomstig aanpaste. Deze stapsgewijze redenering is typerend voor R1, waarbij nauwkeurigheid en grondige analyse belangrijker zijn dan reactiesnelheid.
Wanneer kiest u voor DeepSeek-R1 versus DeepSeek-V3?
Het selecteren van het juiste model – DeepSeek-R1 of DeepSeek-V3 – hangt af van uw taak- of projectvereisten
Een aanbevolen workflow voor de meeste taken is om te beginnen met V3 . Als u een situatie tegenkomt waarin V3 geen geldig antwoord produceert of in een herhalende lus terechtkomt, schakelt u over naar R1.
In sommige gevallen is het verifiëren van de outputkwaliteit eenvoudig – bijvoorbeeld wanneer u een script schrijft dat data samenvat, kunt u het resultaat eenvoudig testen en valideren. Maar met complexe algoritmen of taken die veel redeneren vereisen , wordt het veel moeilijker om de correctheid te beoordelen zonder diepere analyse. Dit is waar duidelijke richtlijnen voor het kiezen van het juiste model essentieel worden.
| Taak | Aanbevolen Model |
|---|---|
| Schrijven, contentcreatie, vertaling | V3 |
| Taken waarbij je de kwaliteit van het resultaat kunt beoordelen | V3 |
| Algemene programmeervragen | V3 |
| AI-assistent taken | V3 |
| Onderzoek en diepgaande verkenning | R1 |
| Complexe wiskunde, codering of logische vragen | R1 |
| Lange, iteratieve gesprekken om een enkel probleem op te lossen | R1 |
| Geïnteresseerd in het begrijpen van het denkproces achter het antwoord | R1 |
Conclusie
DeepSeek-V3 is de optimale keuze voor alledaagse taken zoals schrijven, contentcreatie en snelle codeervragen , evenals AI-assistenttoepassingen waarbij natuurlijke en vloeiende conversatie essentieel is. Het is ook zeer geschikt voor taken waarbij de kwaliteit van de output eenvoudig en snel kan worden geëvalueerd.
Voor complexe uitdagingen die geavanceerde redeneringen vereisen , is DeepSeek-R1 de superieure optie. Of het nu gaat om onderzoek, ingewikkelde coderingsproblemen, wiskundig redeneren of lange probleemoplossende gesprekken , R1’s gestructureerde, stapsgewijze redenering zorgt voor nauwkeurigheid en diepgang bij het aanpakken van deze veeleisende taken.
Door de sterke punten van elk model te begrijpen, kunnen gebruikers de meest effectieve tool kiezen voor hun specifieke behoeften en doelen.